This is about the processors, not the laptops, so commenting on the chips instead. They look great, but they look like they're the M1 design, just more of it. Which is plenty for a laptop! But it'll be interesting to see what they'll do for their desktops.
Most of the additional chip area went into more GPUs and special-purpose video codec hardware. It's "just" two more cores than the vanilla M1, and some of the efficiency cores on the M1 became performance cores. So CPU-bound things like compiling code will be "only" 20-50% faster than on the M1 MacBook. The big wins are for GPU-heavy and codec-heavy workloads.
That makes sense since that's where most users will need their performance. I'm still a bit sad that the era of "general purpose computing" where CPU can do all workloads is coming to an end.
Nevertheless, impressive chips, I'm very curious where they'll take it for the Mac Pro, and (hopefully) the iMac Pro.
Total cores, but going from 4 "high performance" and 4 "efficiency" to 8 "high performance" and 2 "efficiency. So should be more dramatic increase in performance than "20% more cores" would provide.
Yes. But the 14" and 16" has larger battery than 13" MacBook Pro or Air. And they were designed for performance, so two less EE core doesn't matter as much.
It is also important to note, despite the name with M1, we dont know if the CPU core are the same as the one used in M1 / A14. Or did they used A15 design where the energy efficient core had significant improvement. Since the Video Decoder used in M1 Pro and Max seems to be from A15, the LPDDR5 is also a new memory controller.
In A15, Anandtech claims the Efficiency cores are 1/3 the performance, but 1/10 the power. They should be looking at (effectively) doubling the power consumption over M1 with just the CPUs and assuming they don't increase clockspeeds.
Going from 8 to 16 or 32 GPU cores is another massive power increase.
I wonder if Apple will give us a 'long-haul' mode where the system is locked to only the energy efficient cores and settings. I us developer types would love a computer that survives 24 hours on battery.
macOS Monterey coming out on the 25th has a new Low Power Mode feature that may do just that. That said, these Macs are incredibly efficient for light use, you may already get 24 hrs of battery life with your workload. Not counting screen off time.
Video playback is accelerated by essentially custom ASIC processing built into the CPU, so it's one of the most efficient things you can do now. Most development workloads are far more compute intensive.
I get about 14-16 hours out of my M1 MacBook Air doing basically full-time development (browser, mail client, Slack, text editor & terminal open, and compiling code periodically).
I know everyone's use case is different, but most of my development workload is 65% typing code into a text editor and 35% running it. I'm not continually pegging the CPU, just intermittently, in which case the existence of low power cores help a lot. The supposed javascript acceleration in the M1 has seemed to really speed up my workloads too.
This is true, but it's not worst case by far. Most video is 24 or 30 fps, so about half the typical 60 hz refresh rate. Still a nice optimization path for video. I'm not sure what effect typing in an editor will have on screen refresh, but if the Electron issue is any indication, it's probably complicated.
the power supply is for charging the battery faster. the new magsafe 3 system can charge with more wattage than usb-c, as per the announcement. usb-c max wattage is 100 watts, which was the previous limiting factor for battery charge.
That's with 2 connectors right? I have a Dell Precision 3760 and the one connector charging mode is limited to around 90W. With two connectors working in tandem (they snap together), it's 180W.
The connectors never get remotely warm .. in fact under max charge rate they're consistently cool to touch, so I've always thought that it could probably be increased a little bit with no negative consequences.
Single connector, the 3.1 spec goes up to 5A at 48V. You need new cables with support for the higher voltages, but your "multiple plugs for more power" laptop is exactly the sort of device it's designed for.
I’ve not seen any manufacturer even announce they were going to make a supported cable yet, let alone seen one that does. I might’ve missed it though. This will only make the hell of USB-C cabling worse imho.
The USB Implementers Forum announced a new set of cable markings for USB 4 certified cables that will combine information on the maximum supported data rate and maximum power delivery for a given cable.
The 16” has a 100wh battery, so it needs 100w of power to charge 50% in 30 minutes (their “fast charging”). Add in 20w to keep the laptop running at the same time, and some conversion losses, and a 140w charger sounds just about right.
Sure, but it's an Apple cable plugging into an Apple socket. They don't have to be constrained by the USB-C specs and could implement a custom high power charging mode. In fact I believe some other laptop manufacturers already do this.
I’m not particularly surprised. They have little to prove with the iPhone, but have every reason to make every measurable factor of these new Macs better than both the previous iteration and the competition. Throwing in a future-model-upsell is negligible compared to mixed reviews about Magsafe 3 cluttering up reviews they otherwise expect to be positive.
Just in case people missed it - the magsafe cable connects to the power supply via usb-c. So (in theory) there's nothing special about the charger that you couldn't do with a 3rd party charger, or a multiport charger or something like that.
MagSafe was a gimmick for me - disconnects far too easy, cables fray in like 9 months, only one side, proprietary and overpriced. Use longer cables and they will never be yanked again. MBP is heavy enough that even USB-C is getting pulled out on a good yank.
I briefly had an M1 Macbook Air and the thing I hated the most about it was the lack of Magsafe. I returned it (needed more RAM) and was overjoyed they brought Magsafe back with these and am looking forward to having it on my new 16"
You can also still charge through USB C if you don't care for Magsafe.
Might be a power limitation. I have an XPS 17 which only runs at full performance and charges the battery with the supplied 130W charger. USB C is only specced to 100W. I can still do most things on the spare USB C charger I have.
I have a top-spec 15” MBP that was the last release just before 16”. It has 100W supply and it’s easy to have total draw more than that (so pulling from the battery while plugged in) while running heavy things like 3D games. I’ve seen around 140W peak. So a 150W supply seems prudent.
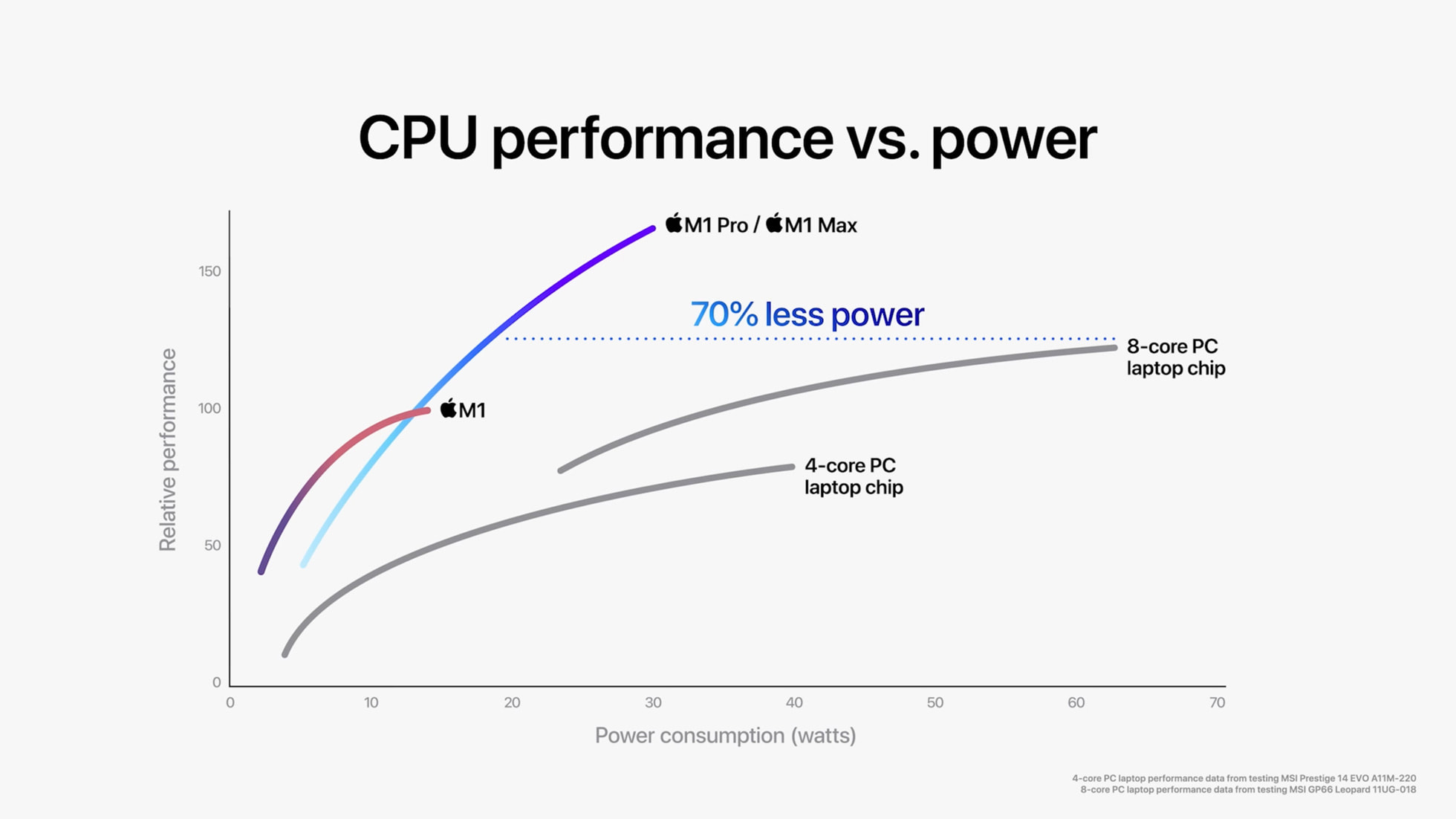
In the power/performance curves provided by Apple, they imply that the Pro/Max provides the same level of performance at a slightly lower power consumption than the original M1.
But at the same time, Apple isn't providing any hard data or explaining their methodology. I dunno how much we should be reading into the graphs. /shrug
Yes, but only at the very extreme. It's normal that a high core count part at low clocks has higher efficiency (perf/power) at a given performance level than a low core count part at high clocks, since power grows super-linearly with clock speed (decreasing efficiency). But notably they've tuned the clock/power regime of the M1 Pro/Max CPUs that the crossover region here is very small.
I think this is pretty easy to math: M1 has 2x the efficiency cores of these new models. Those cores do a lot of work in measured workloads that will sometimes be scheduled on performance cores instead. The relative performance and efficiency lines up pretty well if you assume that a given benchmark is utilizing all cores.
> M1 Pro delivers up to 1.7x more CPU performance at the same power level and achieves the PC chip’s peak performance using up to 70 percent less power
> I'm still a bit sad that the era of "general purpose computing" where CPU can do all workloads is coming to an end.
You'd have to be extremely old to remember that era. Lots of stuff important to making computers work got split off into separate chips away from the CPU pretty early into mass computing, such as sound, graphics, and networking. We've also been sending a lot of compute from the CPU into the GPU as late for both graphics and ML purposes.
Lately it seems like the trend has been taking these specialized peripheral chips and moving them back into SoC packages. Apple's approach here seems to be an evolutionary step on top of say, an Intel chip with integrated graphics, rather than a revolutionary step away from the era of general purpose computing.
The IBM PC that debuted with the 286 was the PC/AT ("Advanced Technology", hah) that is best known for introducing the AT bus later called the ISA bus that led to the proliferation of video cards, sound cards, and other expansion cards that made the PC what it is today.
I'm actually not sure there ever was a "true CPU computer age" where all processing was CPU-bound/CPU-based. Even the deservedly beloved MOS 6502 processor that powered everything for a hot decade or so was considered merely a "micro-controller" rather than a "micro-processor" and nearly every use of the MOS 6502 involved a lot of machine-specific video chips, memory management chips. The NES design lasted so long in part because toward then end cartridges would sometimes have entirely custom processing chips pulling work off the MOS 6502.
Even the mainframe era term itself "Central Processing Unit" has always sort of implied it always works in tandem with other "processing units", it's just the most central. (In some mainframe designs I think this was even quite literal in floorplan.) Of course too, when your CPU is a massive tower full of boards that make up individual operations and very the opposite of an Integrated Circuit, it's quite tough to call those a "general purpose CPU" as we imagine them today.
The C64 mini runs on an ARM processor, so that doesn't count in this context. Also I just learned that the processor in the C64 had two coprocessors for sound and graphics (?). So maybe that also doesn't count.
400GB/s available to the CPU cores in a unified memory, that is going to really help certain workloads that are very memory dominant on modern architectures. Both Intel and AMD are solving this with ever increasing L3 cache sizes but just using attached memory in a SOC has vastly higher memory bandwidth potential and probably better latency too especially on work that doesn't fit in ~32MB of L3 cache.
The M1 still uses DDR memory at the end of the day, it's just physically closer to the core. This is in contrast to L3 which is actual SRAM on the core.
The DDR being closer to the core may or may not allow the memory to run at higher speeds due to better signal integrity, but you can purchase DDR4-5333 today whereas the M1 uses 4266.
The real advantage is the M1 Max uses 8 channels, which is impressive considering that's as many as an AMD EPYC, but operates at like twice the speed at the same time.
Just to underscore this, memory physically closer to the cores has improved tRAS times measured in nanoseconds. This has the secondary effect of boosting the performance of the last-level cache since it can fill lines on a cache miss much faster.
The step up from DDR4 to DDR5 will help fill cache misses that are predictable, but everybody uses a prefetcher already, the net effect of DDR5 is mostly just better efficiency.
The change Apple is making, moving the memory closer to the cores, improves unpredicted cache misses. That's significant.
> Just to underscore this, memory physically closer to the cores has improved tRAS times measured in nanoseconds.
I doubt that tRAS timing is affected by how close / far a DRAM chip is from the core. Its just a RAS command after all: transfer data from DRAM to the sense-amplifiers.
If tRAS has improved, I'd be curious how it was done. Its one of those values that's basically been constant (on a nanosecond basis) for 20 years.
Most DDR3 / DDR4 improvements have been about breaking up the chip into more-and-more groups, so that Group#1 can be issued a RAS command, then Group#2 can be issued a separate RAS command. This doesn't lower latency, it just allows the memory subsystem to parallelize the requests (increasing bandwidth but not improving the actual command latency specifically).
The physically shorter wiring is doing basically nothing. That's not where any of the latency bottlenecks are for RAM. If it was physically on-die, like HBM, that'd be maybe different. But we're still talking regular LPDDR5 using off the shelf dram modules. The shorter wiring would potentially improve signal quality, but ground shields do that, too. And Apple isn't exceeding any specs on this (ie, it's not overclocked), so above average signal integrity isn't translating into any performance gains anyway.
Apple also uses massive cache sizes, compared to the industry.
They put a 32 megabyte system level cache in their latest phone chip.
>at 32MB, the new A15 dwarfs the competition’s implementations, such as the 3MB SLC on the Snapdragon 888 or the estimated 6-8MB SLC on the Exynos 2100
> Apple also uses massive cache sizes, compared to the industry.
AMD's upcoming Ryzen are supposed to have 192MB L3 "v-cache" SRAM stacked above each chiplet. Current chiplets are 8-core. I'm not sure if this is a single chiplet but supposedly good for 2Tbps[1].
Slightly bigger chip than a iphone chip yes. :) But also wow a lot of cache. Having it stacked above rather than built in to the core is another game-changing move, since a) your core has more space b) you can 3D stack many layers of cache atop.
This has already been used on their GPUs, where the 6800 & 6900 have 128MB of L3 "Infinity cache" providing 1.66TBps. It's also largely how these cards get by with "only" 512GBps worth of GDDR6 feeding them (256bit/quad-channel... at 16GT). AMD's R9 Fury from spring 2015 had 1TBps of HBM2, for compare, albeit via that slow 4096bit wide interface.
Anyhow, I'm also in awe of the speed wins Apple got here from bringing RAM in close. Cache is a huge huge help. Plus 400GBps main memory is truly awesome, and it's neat that either the CPU or GPU can make use of it.
> The M1 still uses DDR memory at the end of the day, it's just physically closer to the core. This is in contrast to L3 which is actual SRAM on the core.
But they're probably using 8-channels of LPDDR5, if this 400GB/s number is to be believed. Which is far more memory channels / bandwidth than any normal chip released so far, EPYC and Skylake-server included.
It's more comparable to the sort of memory bus you'd typically see on a GPU... which is exactly what you'd hope for on a system with high-end integrated graphics. :)
You'd expect HBM or GDDR6 to be used. But this is seemingly LPDDR5 that's being used.
So its still quite unusual. Its like Apple decided to take commodity phone-RAM and just make many parallel channels of it... rather than using high-speed RAM to begin with.
HBM is specifically designed to be soldered near a CPU/GPU as well. For them to be soldering commodity LPDDR6 is kinda weird to me.
---------
We know it isn't HBM because HBM is 1024-bits at lower clock speeds. Apple is saying they have 512-bits across 8 channels (64-bits per channel), which is near LPDDR5 / DDR kind of numbers.
200GBps is within the realm of 1x HBM channel (1024-bit at low clock speeds), and 400GBps is 2x HBM channels (2048-bit bus at low clock speeds).
> The DDR being closer to the core may or may not allow the memory to run at higher speeds due to better signal integrity, but you can purchase DDR4-5333 today whereas the M1 uses 4266.
My understanding is that bringing the RAM closer increases the bandwidth (better latency and larger buses), not necessarily the speed of the RAM dies. Also, if I am not mistaken, the RAM in the new M1s is LP-DDR5 (I read that, but it did not stay long on screen so I could be mistaken). Not sure how it is comparable with DDR4 DIMMs.
The overall bandwidth isn't affected much by the distance alone. Latency, yes, in the sense that the signal literally has to travel further, but that difference is miniscule (like 1/10th of a nanosecond) compared to overall DDR access latencies.
Better signal integrity could allow for larger busses, but I don't think this is actually a single 512 bit bus. I think it's multiple channels of smaller busses (32 or 64 bit). There's a big difference from an electrical design perspective (byte lane skew requirements are harder to meet when you have 64 of them). That said, I think multiple channels is better anyway.
The original M1 used LPDDR4 but I think the new ones use some form of DDR5.
Your comment got me thinking, and I checked the math. It turns out that light takes ~0.2 ns to travel 2 inches. But the speed of signal propagation in copper is ~0.6 c, so that takes it up to 0.3 ns. So, still pretty small compared to the overall latencies (~13-18 ns for DDR5) but it's not negligible.
I do wonder if there are nonlinearities that come in to play when it comes to these bottlenecks. Yes, by moving the RAM closer it's only reducing the latency by 0.2 ns. But, it's also taking 1/3rd of the time that it used to, and maybe they can use that extra time to do 2 or 3 transactions instead. Latency and bandwidth are inversely related, after all!
Well, you can have high bandwidth and poor latency at the same time -- think ultra wide band radio burst from Earth to Mars -- but yeah, on a CPU with all the crazy co-optimized cache hierarchies and latency hiding it's difficult to see how changing one part of the system changes the whole. For instance, if you switched 16GB of DRAM for 4GB of SRAM, you could probably cut down the cache-miss latency a lot -- but do you care? If you cache hit rate is high enough, probably not. Then again, maybe chopping the worst case lets you move allocation away from L3 and L2 and into L1, which gets you a win again.
I suspect the only people who really know are the CPU manufacturer teams that run PIN/dynamorio traces against models -- and I also suspect that they are NDA'd through this life and the next and the only way we will ever know about the tradeoffs are when we see them pop up in actual designs years down the road.
DRAM latencies are pretty heinous. It makes me wonder if the memory industry will go through a similar transition to the storage industry's HDD->SSD sometime in the not too distant future.
I wonder about the practicalities of going to SRAM for main memory. I doubt silicon real estate would be the limiting factor (1T1C to 6T, isn't it?) and Apple charges a king's ransom for RAM anyway. Power might be a problem though. Does anyone have figures for SRAM power consumption on modern processes?
>> I wonder about the practicalities of going to SRAM for main memory. I doubt silicon real estate would be the limiting factor (1T1C to 6T, isn't it?) and Apple charges a king's ransom for RAM anyway. Power might be a problem though. Does anyone have figures for SRAM power consumption on modern processes?
I've been wondering about this for years. Assuming the difference is similar to the old days, I'd take 2-4GB of SRAM over 32GB of DRAM any day. Last time this came up people claimed SRAM power consumption would be prohibitive, but I have a hard time seeing that given these 50B transistor chips running at several GHz. Most of the transistors in an SRAM are not switching, so they should be optimized for leakage and they'd still be way faster than DRAM.
> The overall bandwidth isn't affected much by the distance alone.
Testing showed that the M1's performance cores had a surprising amount of memory bandwidth.
>One aspect we’ve never really had the opportunity to test is exactly how good Apple’s cores are in terms of memory bandwidth. Inside of the M1, the results are ground-breaking: A single Firestorm achieves memory reads up to around 58GB/s, with memory writes coming in at 33-36GB/s. Most importantly, memory copies land in at 60 to 62GB/s depending if you’re using scalar or vector instructions. The fact that a single Firestorm core can almost saturate the memory controllers is astounding and something we’ve never seen in a design before.
It just said that bandwidth between a performance core and memory controller is great. It's not related to distance between memory controller and DRAM.
As far as I'm aware, IBM is one of the few chip-designers who have eDRAM capabilities.
IBM has eDRAM on a number of chips in varying capacities, but... its difficult for me to think of Intel, AMD, Apple, ARM, or other chips that have eDRAM of any kind.
Intel had one: the eDRAM "Crystalwell" chip, but that is seemingly a one-off and never attempted again. Even then, this was a 2nd die that was "glued" onto the main chip, and not like IBM's truly eDRAM (embedded into the same process).
You're right. My bad. It's much less common than I'd thought.
(Intel had it on a number of chips that included the Iron Pro Graphics across Haswell, Broadwell, Skylake etc)
Crystalwell was the codename for the eDRAM that was grafted onto Broadwell. (EDIT: Apparently Haswell, but... yeah. Crystalwell + Haswell for eDRAM goodness)
Good point. Especially since a lot of software these days is not all that cache friendly. Realistically this means we have 2 years or so till further abstractions eat up the performance gains.
I thought the memory was one of the more interesting bits here.
My 2-year-old Intel MBP has 64 GB, and 8 GB of additional memory on the GPU. True, on the M1 Max you don't have to copy back and forth between CPU and GPU thanks to integrated memory, but the new MBP still has less total memory than my 2-year-old Intel MBP.
And it seems they just barely managed to get to 64 GiB. The whole processor chip is surrounded by memory chips. That's in part why I'm curious to see how they'll scale this. One idea would be to just have several M1 Max SoCs on a board, but that's going to be interesting to program. And getting to 1 TB of memory seems infeasible too.
Just some genuine honest curiosity here; how many workloads actually require 64gb of ram? For instance, I'm an amateur in the music production scene, and I know that sampling heavy work
flows benefit from being able to load more audio clips fully into RAM rather than streaming them from disk. But 64g seems a tad overkill even for that.
I guess for me I would prefer an emphasis on speed/bandwidth rather than size, but I'm also aware there are workloads that I'm completely ignorant of.
Same, I tend to get everything in 32GB but more and more often I'm going over that and having things slow down. I've also nuked an SSD in a 16GB MBP due to incredibly high swap activity. It would make no sense for me to buy another 32GB machine if I want it to last five years.
Another anecdote from someone who is also in the music production scene - 32GB tended to be the "sweet spot" in my personal case for the longest time, but I'm finding myself hitting the limits more and more as I continue to add more orchestral tracks which span well over 100 tracks total in my workflows.
I'm finding I need to commit and print a lot of these. Logic's little checker in the upper right showing RAM, Disk IO, CPU, etc also show that it is getting close to memory limits on certain instruments with many layers.
So as someone who would be willing to dump $4k into a laptop where its main workload is only audio production, I would feel much safer going with 64GB knowing there's no real upgrade if I were to go with the 32GB model outside of buying a totally new machine.
Edit: And yes, there is does show the typical "fear of committing" issue that plagues all of us people making music. It's more of a "nice to have" than a necessity, but I would still consider it a wise investment. At least in my eyes. Everyone's workflow varies and others have different opinions on the matter.
I know the main reason why the Mac Pro has options for LRDIMMs for terabytes of RAM is specifically for audio production, where people are basically using their system memory as cache for their entire instrument library.
I have to wonder how Apple plans to replace the Mac Pro - the whole benefit of M1 is that gluing the memory to the chip (in a user-hostile way) provides significant performance benefits; but I don't see Apple actually engineering a 1TB+ RAM SKU or an Apple Silicon machine with socketed DRAM channels anytime soon.
I think we'd probably see apple use the fast and slow ram method that old computers used back in the 90's.
16-32GB of RAM on the SOC, with DRAM sockets for usage past the built in amount.
Though by the time we see an ARM MacPro they might move to stacked DRAM on the SOC. But i'd really think two tier memory system would be apple's method of choice.
I'd also expect a dual SOC setup.
So I don't expect to see that anytime soon.
I'd love to get my hands on a Mac Mini with the M1 Max.
I went for 64GB. I have one game where 32GB is on the ragged edge - so for the difference it just wasn't worth haggling over. Plus it doubled the memory bandwidth - nice bonus.
And unused RAM isn't wasted - the system will use it for caching. Frankly I see memory as one of the cheapest performance variables you can tweak in any system.
> how many workloads actually require 64gb of ram?
Don't worry, Chrome will eat that up in no time!
More seriously, I look forward to more RAM for some of the datasets I work with. At least so I don't have to close everything else while running those workloads.
As a data scientist, I sometimes find myself going over 64 GB. Of course it all depends on how large data I'm working on. 128 GB RAM helps even with data of "just" 10-15 GB, since I can write quick exploratory transformation pipelines without having to think about keeping the number of copies down.
I could of course chop up the workload earlier, or use samples more often. Still, while not strictly necessary, I regularly find I get stuff done quicker and with less effort thanks to it.
Not many, but there are a few that need even more. My team is running SQL servers on their laptops (development and support) and when that is not enough, we go to Threadrippers with 128-256GB of RAM. Other people run Virtual Machines on their computers (I work most of the time in a VM) and you can run several VMs at the same time, eating up RAM really fast.
On a desktop Hackintosh, I started with 32GB that would die with out of memory errors when I was processing 16bit RAW images at full resolution. Because it was Hackintosh, I was able to upgrade to 64GB so the processing could complete. That was the only thing running.
What image dimensions? What app? I find this extremely suspect, but it’s plausible if you’ve way undersold what you’re doing. 24Mpixel 16bit RAW image would have no problem generally on an 4gb machine if it’s truly the only app running and the app isn’t shit. ;)
I shoot timelapse using Canon 5D RAW images, I don't know the exact dimensions off the top of my head but greater than 5000px wide. I then grade them using various programs, ultimately using After Effects to render out full frame ProRes 4444. After Effects was running out of memory. It would crash and fail to render my file. It would display an error message that told me specifically it was out of memory. I increased the memory available to the system. The error goes away.
But I love the fact that you have this cute little theory to doubt my actual experience to infer that I would make this up.
> But I love the fact that you have this cute little theory to doubt my actual experience to infer that I would make this up.
The facts were suspect, your follow up is further proof I had good reason to be suspect. First off, the RAW images from a 5D aren’t 16 bit. ;) Importantly, the out of memory error had nothing to do with the “16 bit RAW files”, it was video rendering lots of high res images that was the issue which is a very different issue and of course lots of RAM is needed there. Anyway, notice I said “but it’s plausible if you’ve way undersold what you’re doing”, which is definitely the case here, so I’m not sure why it bothered you.
>> die with out of memory errors when I was processing 16bit RAW images
> Canon RAW images are 14bit
You don’t see the issue?
> Are you just trying to be argumentative for the fun?
In the beginning, I very politely asked a clarifying question making sure not to call you a liar as I was sure there was more to the story. You’re the one who’s been defensive and combative since, and honestly misrepresenting facts the entire time. Where you wrong at any point? Only slightly, but you left out so many details that were actually important to the story for anyone to get any value out of your anecdata. Thanks to my persistence, anyone who wanted to learn from your experience now can.
>> I was processing 16bit RAW images at full resolution.
>> ...using After Effects to render out full frame ProRes 4444.
Those are two different applications to most of us. No one is accusing you of making things up, just that the first post wasn't fully descriptive of your use case.
Working with video will use up an extraordinary amount of memory.
Some of the genetics stuff I work on requires absolute gobs of RAM. I have a single process that requires around 400GB of RAM that I need to run quite regularly.
It’s a slight exaggeration, I also have an editor open and some dev process (test runner usually). It’s not just caching, I routinely hit >30 GB swap with fans revved to the max and fairly often this becomes unstable enough to require a reboot even after manually closing as much as I can.
I mean, some of this comes down to poor executive function on my part, failing to manage resources I’m no longer using. But that’s also a valid use case for me and I’m much more effective at whatever I’m doing if I can defer it with a larger memory capacity.
Since applications have virtual memory, it sort of doesn’t matter? The OS will map these to actual pages based on how many processes are available, etc. So if only one app runs and it wants lots of memory, it makes sense to give it lots of memory - that is the most “economical” decision from both a energy and performance POV.
So, M1 has been out for a while now, with HN doom and gloom about not being able to put enough memory into them. Real world usage has demonstrated far less memory usage than people expected (I don't know why, maybe someone paid attention and can say). The result is that 32G is a LOT of memory for an M1-based laptop, and 64G is only needed for very specific workloads I would expect.
Measuring memory usage is a complicated topic and just adding numbers up overestimates it pretty badly. The different priorities of memory are something like 1. wired (must be in RAM) 2. dirty (can be swapped) 3. purgeable (can be deleted and recomputed) 4. file backed dirty (can be written to disk) 4. file backed clean (can be read back in).
Also note M1's unified memory model is actually worse for memory use not better. Details left as an exercise for the reader.
Unified memory is a performance/utilisation tradeoff. I think the thing is it's more of an issue with lower memory specs. The fact you don't have 4GB (or even 2 GB) dedicated memory on a graphics card in a machine with 8GB of main memory is a much bigger deal than not having 8GB on the graphics card on a machine with 64 GB of main RAM.
Or like games, even semi-casual ones. Civ6 would not load at all on my mac mini. Also had to fairly frequently close browser windows as I ran out of memory.
I couldn't load Civ6 until I verified game files in Steam, and now it works pretty perfectly. I'm on 8GB and always have Chrome, Apple Music and OmniFocus running alongside.
I'm interested to see how the GPU on these performs, I pretty much disable the dGPU on my i9 MBP because it bogs my machine down. So for me it's essentially the same amount of memory.
From the perspective of your GPU, that 64GB of main memory attached to your CPU is almost as slow to fetch from as if it were memory on a separate NUMA node, or even pages swapped to an NVMe disk. It may as well not be considered "memory" at all. It's effectively a secondary storage tier.
Which means that you can't really do "GPU things" (e.g. working with hugely detailed models where it's the model itself, not the textures, that take up the space) as if you had 64GB of memory. You can maybe break apart the problem, but maybe not; it all depends on the workload. (For example, you can't really run a Tensorflow model on a GPU with less memory than the model size. Making it work would be like trying to distribute a graph-database routing query across nodes — constant back-and-forth that multiplies the runtime exponentially. Even though each step is parallelizable, on the whole it's the opposite of an embarrassingly-parallel problem.)
>The SoC has access to 16GB of unified memory. This uses 4266 MT/s LPDDR4X SDRAM (synchronous DRAM) and is mounted with the SoC using a system-in-package (SiP) design. A SoC is built from a single semiconductor die whereas a SiP connects two or more semiconductor dies.
SDRAM operations are synchronised to the SoC processing clock speed. Apple describes the SDRAM as a single pool of high-bandwidth, low-latency memory, allowing apps to share data between the CPU, GPU, and Neural Engine efficiently.
In other words, this memory is shared between the three different compute engines and their cores. The three don't have their own individual memory resources, which would need data moved into them. This would happen when, for example, an app executing in the CPU needs graphics processing – meaning the GPU swings into action, using data in its memory. https://www.theregister.com/2020/11/19/apple_m1_high_bandwid...
I know; I was talking about the computer the person I was replying to already owns.
The GP said that they already essentially have 64GB+8GB of memory in their Intel MBP; but they don't, because it's not unified, and so the GPU can't access the 64GB. So they can only load 8GB-wide models.
Whereas with the M1 Pro/Max the GPU can access the 64GB, and so can load 64GB-wide models.
How much of that 64 GB is in use at the same time though? Caching not recently used stuff from DRAM out to an SSD isn't actually that slow, especially with the high speed SSD that Apple uses.
Right. And to me, this is the interesting part. There's always been that size/speed tradeoff ... by putting huge amounts of memory bandwidth on "less" main RAM, it becomes almost half-ram-half-cache; and by making the SSD fast it becomes more like massive big half-hd-half-cache. It does wear them out, however.
You were (unintentionally) trolled. My first post up there was alluding to the legend that Bill Gates once said, speaking of the original IBM PC, "640K of memory should be enough for anybody." (N.B. He didn't[0])
Video and VFX generally don't need to keep whole sequences in RAM persistently these days because:
1. The high-end SSDs in all Macs can keep up with that data rate (3GB/sec)
2. Real-time video work is virtually always performed on compressed (even losslessly compressed) streams, so the data rate to stream is less than that.
But it's also been around for at least a year. And upcoming pcie 5 SSDs will up that to 10-14GBps.
I'm saying Apple might have wanted to emphasise their more standout achievements. Such as on the CPU front, where they're likely to be well ahead for a year - competition won't catch up until AMD starts shipping 5nm Zen4 CPUs in Q3/Q4 2022.
I'm guessing that's new for the 13" or for the M1, but my 16‑inch MacBook Pro purchased last year had 64GB of memory. (Looks like it's considered a 2019 model, despite being purchased in September 2020).
Really curious if the memory bandwidth is entirely available to the CPU if the GPU is idle. An nvidia RTX3090 has nearly 1TB/s bandwidth, so the GPU is clearly going to use as much of the 400GB/s as possible. Other unified architectures have multiple channels or synchronization to memory, such that no one part of the system can access the full bandwidth. But if the CPU can access all 400GB/s, that is an absolute game changer for anything memory bound. Like 10x faster than an i9 I think?
Not sure if it will be available, but 400GB/s is way too much for 8 cores to take up. You would need some sort of avx512 to hog up that much bandwidth.
Moreover, it's not clear how much of a bandwidth/width does M1 max CPU interconnect/bus provide.
--------
Edit: Add common sense about HPC workloads.
There is a fundamental idea called memory-access-to-computation ratio. We can't assume a 1:0 ratio since it was doing literally nothing except copying.
Typically your program needs serious fixing if it can't achieve 1:4. (This figure comes from a CUDA course. But I think it should be similar for SIMD)
Edit: also a lot of that bandwidth is fed through cache. Locality will eliminate some orders of magnitudes of memory access, depending on the code.
> Not sure if it will be available, but 400GB/s is way too much for 8 cores to take up. You would need some sort of avx512 to hog up that much bandwidth.
If we assume that frequency is 3.2Ghz and IPC of 3 with well optimized code(which is conservative for performance cores since they are extremely wide) and count only performance cores we get 5 bytes for instruction. M1 supports 128-bit Arm Neon, so peak bandwidth usage per instruction(if I didn't miss anything) is 32 bytes.
Don't know the clock speed but 8 cores at 3Ghz working on 128bit SIMD is 8316 = 384GB/s so we are in the right ball park. Not that I personally have a use for that =) Oh, wait, bloody Java GC might be a use for that. (LOL, FML or both).
But the classic SIMD problem is matrix-multiplication, which doesn't need full memory bandwidth (because a lot of the calculations are happening inside of cache).
The question is: what kind of problems are people needing that want 400GB/s bandwidth on a CPU? Well, probably none frankly. The bandwidth is for the iGPU really.
The CPU just "might as well" have it, since its a system-on-a-chip. CPUs usually don't care too much about main-memory bandwidth, because its like 50ns+ away latency (or ~200 clock ticks). So to get a CPU going in any typical capacity, you'll basically want to operate out of L1 / L2 cache.
> Oh, wait, bloody Java GC might be a use for that. (LOL, FML or both).
For example, I know you meant the GC as a joke. But if you think of it, a GC is mostly following pointer->next kind of operations, which means its mostly latency bound, not bandwidth bound. It doesn't matter that you can read 400GB/s, your CPU is going to read an 8-byte pointer, wait 50-nanoseconds for the RAM to respond, get the new value, and then read a new 8-byte pointer.
Unless you can fix memory latency (and hint, no one seems to be able to do so), you'll be only able to hit 160MB/s or so, no matter how high your theoretical bandwidth is, you get latency locked at a much lower value.
Yeah the marking phase cannot be efficiently vectorized. But I wonder if it can help with compacting/copying phase.
Also for me the process sounds oddly familiar to vmem table walking. There is currently a RISC-V J extension drafting group. I wonder what they can come up with.
But they are demonstrating with 16 cores + 30 GB/s & 128 cores + 190 GB/s. And to my understanding they did not really mention what type of computational load did they perform. So this does not sound too ridiculous. M1 max is pairing 8 cores + 400GB/s.
How do you prefetch "node->next" where "node" is in a linked list?
Answer: you literally can't. And that's why this kind of coding style will forever be latency bound.
EDIT: Prefetching works when the address can be predicted ahead of time. For example, when your CPU-core is reading "array", then "array+8", then "array+16", you can be pretty damn sure the next thing it wants to read is "array+24", so you prefetch that. There's no need to wait for the CPU to actually issue the command for "array+24", you fetch it even before the code executes.
Now if you have "0x8009230", which points to "0x81105534", which points to "0x92FB220", good luck prefetching that sequence.
--------
Which is why servers use SMT / hyperthreading, so that the core can "switch" to another thread while waiting those 50-nanoseconds / 200-cycles or so.
I don't really know how the implementation of a tracing GC works but I was thinking they could do some smart memory ordering to land in the same cache-line as often as possible.
But that’s just the marking phase, isn’t it? And most of it can be done fully in parallel, so while not all CPU cores can be maxed out with that, more often than not the original problem itself can be hard to parallelize to that level, so “wasting” a single core may very well be worth it.
I always like pointing out Knuth's dancing links algorithm for Exact-covering problems. All "links" in that algorithm are of the form "1 -> 2 -> 3 -> 4 -> 5" at algorithm start.
Then, as the algorithm "guesses" particular coverings, it turns into "1->3->4->5", or "1->4", that is, always monotonically increasing.
As such, no dynamic memory is needed ever. The linked-list is "statically" allocated at the start of the program, and always traversed in memory order.
Indeed, Knuth designed the scheme as "imagine doing malloc/free" to remove each link, but then later, "free/malloc" to undo the previous steps (because in Exact-covering backtracking, you'll try something, realize its a dead end, and need to backtrack). Instead of a malloc followed up by a later free, you "just" drop the node out of the linked list, and later reinsert it. So the malloc/free is completely redundant.
In particular: a given "guess" into an exact-covering problem can only "undo" its backtracking to the full problem scope. From there, each "guess" only removes possibilities. So you use the "maximum" amount of memory at program start, you "free" (but not really) nodes each time you try a guess, and then you "reinsert" those nodes to backtrack to the original scope of the problem.
Finally, when you realize that, you might as well put them all into order for not only simplicity, but also for speed on modern computers (prefetching and all that jazz).
Its a very specific situation but... it does happen sometimes.
AMD showed with their Infinity Cache that you can get away with much less bandwidth if you have large caches. It has the side effect of radically reducing power consumption.
Apple put 32MB of cache in their latest iPhone. 128 or even 256MB of L3 cache wouldn't surprise me at all given the power benefits.
Apple put ProMotion in the built in display, so while it can ramp up to 120Hz, it'll idle at more like 24 Hz when showing static content. (the iPad Pro goes all the way down to 10Hz, but some early sources seem to say 24Hz for these MacBook Pros.) There may also be panel self refresh involved, in which case a static image won't even need that much. I bet the display coprocessors will expose the adaptive refresh functionality over the external display connectors as well.
It only takes a tiny animation (eg. a spinner, pulsing glowing background, animated clock, advert somewhere, etc), and suddenly the whole screen is back to 120 Hz refresh.
Don't know much about the graphics on an M1. Does it not render to a framebuffer? Is that framebuffer spread over all 4 memory banks? Can't wait to read all about it.
The updates from the Asahi Linux team are fantastic for getting insights into the M1 architecture. They've not really dug deep into the GPU yet, but that's coming soon.
When nothing is changing, you do not have to touch the GPU. Yes, without Panel Self Refresh there would be this many bits going to the panel at that rate, but the display engine would keep resubmitting the same buffer. No need to rerender when there's no damage. (And when there is, you don't have to rerender the whole screen, only the combined damage of the previous and current frames.)
More memory bandwith = 10x faster than an i9 ? this makes no sense to me doesn't clock speed and cores determine the major part of the performance of a cpu ?
Yes and no. There are many variables to take into account. An example from the early days of the PPC architecture was their ability to pre-empt instructions. This gave performance boasts even in the absence of a higher clock speed. I can't speak specifically on the M1, but there are other things outside of clock speed and cores that determine speed.
Yes, but it's a double edged sword. It means you're using relatively slow ram for the GPU, and that the GPU takes memory bandwidth away from the CPU as well. Traditionally we've ended up with something that looks like Intel's kinda crappy integrated video.
The copying process was never that much of a big deal, but paying for 8GB of graphics ram really is.
> The copying process was never that much of a big deal
I don't know about that? Texture memory management in games can be quite painful. You have to consider different hardware setups and being able to keep the textures you need for a certain scene in memory (or not, in which case, texture thrashing).
The copying process was quite a barrier to using compute (general purpose GPU) to augment CPU processing and you had to ensure that the work farmed to the GPU was worth the cost of the to/from costs. Game consoles of late have generally had unified memory (UMA) and it's quite a nice advantage because moving data is a significant bottleneck.
Using Intel's integrated video as a way to assess the benefits of unified memory is off target. Intel had a multitude of design goals for their integrated GPU and UMA was only one aspect so it's not so easy to single that out for any shortcomings that you seem to be alluding to.
If you're looking at the SKU with the high GPU core count and 64 Gigs of LPDDR5, the total memory bandwidth (400 GBps) isn't that far off from the bandwidth a discrete GPU would have to it's local pool of memory.
You also have an (estimated from die shots) 64 megabyte SRAM system level cache and large L2 and L1 CPU caches, but you are indeed sharing the memory bandwidth between the CPU and GPU.
I'm looking forward to these getting into the hands of testers.
> I'm still a bit sad that the era of "general purpose computing" where CPU can do all workloads is coming to an end.
They’ll still do all workloads, but are optimized for certain workloads. How is that any different than say, a Xeon or EPYC cpu designed for highly threaded (server/scientific computing) applications?
In this context the absence of the 27 inch iMac was interesting. If these SoC were not deemed to be 'right' for the bigger iMac then possibly a more CPU focused / developer focused SoC may be in the works for the iMac?
I doubt they are going to make different chips for prosumer devices. They are going to spread out the M1 pro/max upgrade to the rest of the lineup at some point during the next year, so they can claim "full transition" through their quoted 2 years.
The wildcard is the actual mac pro. I suspect we aren't going to hear about mac pro until next Sept/Oct events, and super unclear what direction they are going to go. Maybe allowing config of multiple M1 max SOCs somehow working together. Seems complicated.
On reflection I think they've decided that their pro users want 'more GPU not more CPU' - they could easily have added a couple more CPU cores but it obviously wasn't a priority.
Agreed that it's hard to see how designing a CPU just for the Mac Pro would make any kind of economic sense but equally struggling to see what else they can do!
I think we will see iMac Pro with incredible performance. Mac Pros, maybe in the next years to come. It's a really high end product to release new specs. Plus, in they release it with M1 Max chips, what would be the difference? a nicer case and more upgrading slot? I don't see the advantage of power. I think Mac Pros will be upgraded like in 2 years ahead
They also have a limited headcount and resources so they wouldn't want to announce M1x/pro/max for all machines now and have employees be idle for the next 3 months.
Notebooks also have a higher profit margin, so they sell them to those who need to upgrade now. The lower-margin systems like Mini will come later. And the Mac Pro will either die or come with the next iteration of the chips.
Yup. Once I saw the 24" iMac I knew the 27" had had it's chips. 30" won't actually be much bigger than the 27" if the bezels shrink to almost nothing - which seems to be the trend.
They're not meant to go together like that -- there's not really an interconnect for it, or any pins on the package to enable something like that. Apple would have to design a new Mx SoC with something like that as an explicit design goal.
I think the problem would be how one chip can access the memory of the other one. The big advantage in the M1xxxx is the unified memory. I don't think the chips have any hardware to support cache coherency and so on spanning more than one chip.
You would have to implement single system image abstraction, if you wanted more than a networked cluster of M1s in a box, in the OS using just software plus virtual memory. You'd use the PCIe as the interconnect. Similar has been done by other vendors for server systems, but it has tradeoffs that would probably not make sense to Apple now.
A more realistic question would be what good hw multisocket SMP support would look like in M1 Max or later chips, as that would be a more logical thing to build if Apple wanted this.
The rumor has long been that the future Mac Pro will use 2-4 of these “M1X” dies in a single package. It remains to be seen how the inter-die interconnect will work / where those IOs are on the M1 Pro/Max die.
The way I interpreted it is that it's like lego so they can add more fast cores or more efficiency cores depending on the platform needs. The successor generations will be new lego building blocks.
Not exactly. M1 CPU, GPU, and RAM were all capped in the same package. New ones appear to be more a single board soldered onto mainboard, with a discrete CPU, GPU, and RAM package each capped individually if their "internals" promo video is to be believed (and it usually is an exact representation of the shipping product) https://twitter.com/cullend/status/1450203779148783616?s=20
Suspect this is a great way for them to manage demand and various yields by having 2 CPU's (or one, if the difference between pro/ max is yield on memory bandwidth) and discrete RAM/ GPU components
I know nothing about hardware, basically. Do Apple’s new GPU cores come close to the capabilities of discrete GPUs like what are used for gaming/scientific applications? Or are those cards a whole different thing?
1. If you're a gamer, this seems comparable to a 3070 Laptop, which is comparable to a 3060 Desktop.
2. If you're a ML researcher you use CUDA (which only works on NVIDIA cards), they have basically a complete software lock unless you want to spend an undefined number of X hundreds of hours fixing and troubleshooting compatibility issues.
There has been an M1 fork of Tensorflow almost since the chip launched last year. I believe Apple did the leg work. It’s a hoop to jump through, yes, and no ones training big image models or transformers with this, but I imagine students or someone sandboxing a problem offline would benefit from the increased performance over CPU only.
Not a great fit. Something like Ampere altra is better as it gives you 80 cores and much more memory which better fits a server. A server benefits more from lots of weaker cores than a few strong cores. The M1 is an awesome desktop/laptop chip and possibly great for HPC, but not for servers.
What might be more interesting is to see powerful gaming rigs built around the these chips. They could have build a kickass game console with these chips.
Why they didn't lean into that aspect of the Apple TV still mystifies me. A Wii-mote style pointing device seems such a natural fit for it, and has proven gaming utility. Maybe patents were a problem?
Why? There are plenty of server oriented ARM platforms available for use (See AWS Graviton). What benefit do you feel Apple’s platform gives over existing ones?
The Apple cores are full custom, Apple-only designs.
The AWS Graviton are Neoverse cores, which are pretty good, but clearly these Apple-only M1 cores are above-and-beyond.
---------
That being said: these M1 cores (and Neoverse cores) are missing SMT / Hyperthreading, and a few other features I'd expect in a server product. Servers are fine with the bandwidth/latency tradeoff: more (better) bandwidth but at worse (highter) latencies.
My understanding is that you don't really need hyperthreading on a RISC CPU because decoding instructions is easier and doesn't have to be parallelised as with hyperthreading.
The DEC Alpha had SMT on their processor roadmap, but it was never implemented as their own engineers told the Compaq overlords that they could never compete with Intel.
"The 21464's origins began in the mid-1990s when computer scientist Joel Emer was inspired by Dean Tullsen's research into simultaneous multithreading (SMT) at the University of Washington."
Okay, the whole RISC thing is stupid. But ignoring that aspect of the discussion... POWER9, one of those RISC CPUs, has 8-way SMT. Neoverse E1 also has SMT-2 (aka: 2-way hyperthreading).
SMT / Hyperthreading has nothing to do with RISC / CISC or whatever. Its just a feature some people like or don't like.
RISC CPUs (Neoverse E1 / POWER9) can perfectly do SMT if the designers wanted.
Don’t think that is entirely true. Lots of features which exist on both RISC and CISC CPUs have different natural fit. Using micro-ops e.g. on a CISC is more important than in RISC CPU even if both benefit. Likewise pipelining has a more natural fit on RISC than CISC, while micro-op cache is more important on CISC than RISC.
I don't even know what RISC or CISC means anymore. They're bad, non-descriptive terms. 30 years ago, RISC or CISC meant something, but not anymore.
Today's CPUs are pipelined, out-of-order, speculative, superscalar, (sometimes) SMT, SIMD, multi-core with MESI-based snooping for cohesive caches. These words actually have meaning (and in particular, describe a particular attribute of performance for modern cores).
RISC or CISC? useful for internet flamewars I guess but I've literally never been able to use either term in a technical discussion.
-------
I said what I said earlier: this M1 Pro / M1 Max, and the ARM Neoverse cores, are missing SMT, which seems to come standard on every other server-class CPU (POWER9, Intel Skylake-X, AMD EPYC).
Neoverse N1 makes up for it with absurdly high core counts, so maybe its not a big deal. Apple M1 however has very small core counts, I doubt that Apple M1 would be good in a server setting... at least not with this configuration. They'd have to change things dramatically to compete at the higher end.
POWER9, RISC-V, and ARM all have microcoded instructions. In particular, division, which is very complicated.
As all CPUs have decided that hardware-accelerated division is a good idea (and in particular: microcoded, single-instruction division makes more sense than spending a bunch of L1 cache on a series of instructions that everyone knows is "just division" and/or "modulo"), microcode just makes sense.
The "/" and "%" operators are just expected on any general purpose CPU these days.
30 years ago, RISC processors didn't implement divide or modulo. Today, all processors, even the "RISC" ones, implement it.
It's slightly more general than that, hiding inefficient use of functional units. A lot of times that's totally memory latency causing the inability to keep FUs fed like you say, but i've seen other reasons, like a wide but diverse set of FUs that have trouble applying to every workload.
The classic reason quoted for SMT is to allow the functional units to be fully utilised when there is instruction-to-instruction dependencies - that is, the input of one instruction is the output from the previous instruction. Doing SMT allow you to create one large pool of functional units and share them between multiple threads, hopefully increasing the chances that they will be fully used.
Well, tons, there isn't another ARM core that can match a single M1 Firestorm, core to core. Heck, only the highest performance x86 cores can match a Firestorm core. and that's just raw performance, not even considering power efficiency. But of course, Apple's not sharing.
They were, but have stopped talking about that for years. The project is probably canceled; I've heard Jim Keller talk about how that work was happening simultaneously with Zen 1.
{kind=link}
Most of the additional chip area went into more GPUs and special-purpose video codec hardware. It's "just" two more cores than the vanilla M1, and some of the efficiency cores on the M1 became performance cores. So CPU-bound things like compiling code will be "only" 20-50% faster than on the M1 MacBook. The big wins are for GPU-heavy and codec-heavy workloads.
That makes sense since that's where most users will need their performance. I'm still a bit sad that the era of "general purpose computing" where CPU can do all workloads is coming to an end.
Nevertheless, impressive chips, I'm very curious where they'll take it for the Mac Pro, and (hopefully) the iMac Pro.