Snowflake seems like it's been losing relevance ever since Clickhouse became more popular. Seems like they're struggling to maintain performance vs the other competitors out there. Not sure how this acquisition will help here. I don't think decoupling storage and compute was a good bet in the long run.
Thats interesting, i don't see these as occupying the same space. Clickhouse is in the space of realtime analytics and Snowflake is a data warehouse. Although you could use Clickhouse for similar things it will fail at doing large distributed joins and similarly Snowflake will have trouble meeting a subsecond SLO.
also FWIW Clickhouse's cloud offering also decouples storage and compute using an object store, but they found a good middleground where they keep local caches of hot data.
But CH is capable of the same “data warehousing” features that snowflake is. Which leaves snowflake as a slower, less capable, less open, and more expensive alternative.
Which brings me to the next point: I’m convinced the delineation between “data warehouse” and “olap” is largely a marketing move designed to segment the market along made up boundaries.
Snowflake and ClickHouse are very different in their focus.
Snowflake is focused on enterprise customers. It has a lot of features focused on that, like very granular security and governance and data marketplace. There's also some non-enterprise features that ClickHouse lacks, like the ability to execute Python in database (so you can bring ML in).
But the biggest difference is that Snowflake is storage segregated architecture. Scaling Snowflake is done by running "alter warehouse resize" or something. You can also dedicate specific compute slices to specific users and scale them up and down as needed. And this is all managed for you.
If you want to run ClickHouse at scale, you have to run your own k8s, figure out how to manage persistent storage, figure out how to replicate your data, manage cluster replicated tables, etc. Once you outgrow single instance, things get exponentially more difficult - both for the admins and for the users.
Also, while ClickHouse can do joins and is getting better and better optimizer as we speak, and is probably faster than Snowflake for the same money on "single big table analytics" kind of workload, I would expect it to perform much worse in traditional analytics queries, like you would find in TPC-DS.
> If you want to run ClickHouse at scale, you have to run your own k8s, figure out how to manage persistent storage, figure out how to replicate your data, manage cluster replicated tables, etc. Once you outgrow single instance, things get exponentially more difficult - both for the admins and for the users.
This greatly overstates the difficulty of running ClickHouse as well as the current state of the market.
1. ClickHouse has a good Kubernetes operator written by Altinity that manages most of the basic Kubernetes operations. It's used to operate many thousands of ClickHouse clusters worldwide both self-managed environments as well as multiple SaaS offerings of ClickHouse. (Disclaimer: it's written by my company.)
2. If you don't want the trouble of running ClickHouse there are now multiple cloud vendors in every geographic region offering ClickHouse-as-a-Service. Among other things competition keeps prices reasonable and ensures plenty of choice for users.
There are real differences between Snowflake and ClickHouse but ease of operation is no longer one of them. For example one major difference between Snowflake and ClickHouse from a user perspective is the following: You can develop great Snowflake applications just with a knowledge of SQL whereas for ClickHouse you really have to know how it works inside.
Yeah, that would be my answer as well. I actually forgot to mention that - Snowflake and the like store data away from compute so no matter how you misconfigure clusters (though Snowflake isn't really that configurable) the data is safe. Messing up database that stores data locally means the data is gone - and that makes all operations like resizes and upgrades much more scary.
But of course the local storage is much faster. Tradeoffs.
I know ClickHouse Cloud uses S3 as well, but I don't know much about it, so I don't want to comment on it.
We use both MS SQL and Snowflake heavily. There are clearly instances where having row based storage is appropriate, and also instances where columnar storage outperforms. All based on your workload and not just marketing.
MSSQL is an OLTP based db (going to preclude discussion of its fancy column index stuff it’s capable of). OLTP db’s definitely, definitely have a different role.
I’m talking about the false difference between the likes of ClickHouse and Snowflake, where they’re both column oriented already. I’m asserting that the fundamental differences between “classic” column db’s and “data warehouses” is far less fundamental than the marketing would have us believe. Some of the db’s in this space have slightly different architectures and trade offs, and some deliberately operate at different scales, but they are built for, and operate in, basically the same purpose.
I think it's more borne of the lack of scaling capabilities in the traditional sql databases, and I guess a lack of capability in summarising data.
In reality, you can probably scale something like vitess pretty far, and then by adding your own summary tables on top, you're probably good for most usecases.
I'm not an expert on this level of the stack though, so I'm probably missing a whole bunch of context.
What I’ve seen: most big companies have one or a few Oracle databases and hundreds or thousands of “all other DBs”, including licenses for MS SQL Server.
Corporate and education is infested with Oracle due to an army of salesdroids and large technical platform decisions being made by upper mgmt instead of infra staff.
I've also observed that Oracle stack people generally don't have experience with other platforms, so push it in whatever org they're working for.
Sounds like that's a you issue, not one for Oracle.
Don't mean to sound dismissive but that what your post reads like, jut because I've never encountered a brown rat does not mean it's not the most populous animal species on earth
It's extremely possible to have never run into an Oracle DB in an entire career (in the depts you worked in), and moreover it's quite possible to use one database in finance and another in engineering or operations (Postgres or cloud). It merely means you haven't worked at the type and size of organization that tends to license Oracle, or more specifically only in some depts. And sometimes the org didn't voluntarily pick Oracle for technical reasons, it was mandated by the end-user, or for compliance, or application stack, or Oracle's sales team beat out technically superior/more cost-efficient competitors.
None of that is denying Oracle exists.
And that isn't even an 'issue', just an observation. I imagine this used to be similar with encountering IBM DB2 or SAP or Amdahl or melamine deskphones and partitions, but I assume you wouldn't say those are issues.
Pretty sure the most populous animal species on earth would be some type of insect, probably an ant or a locust. According to wikipedia there are estimated to be over 1.4 billion insects for each human on Earth. Rats are numerous but not nearly that numerous.
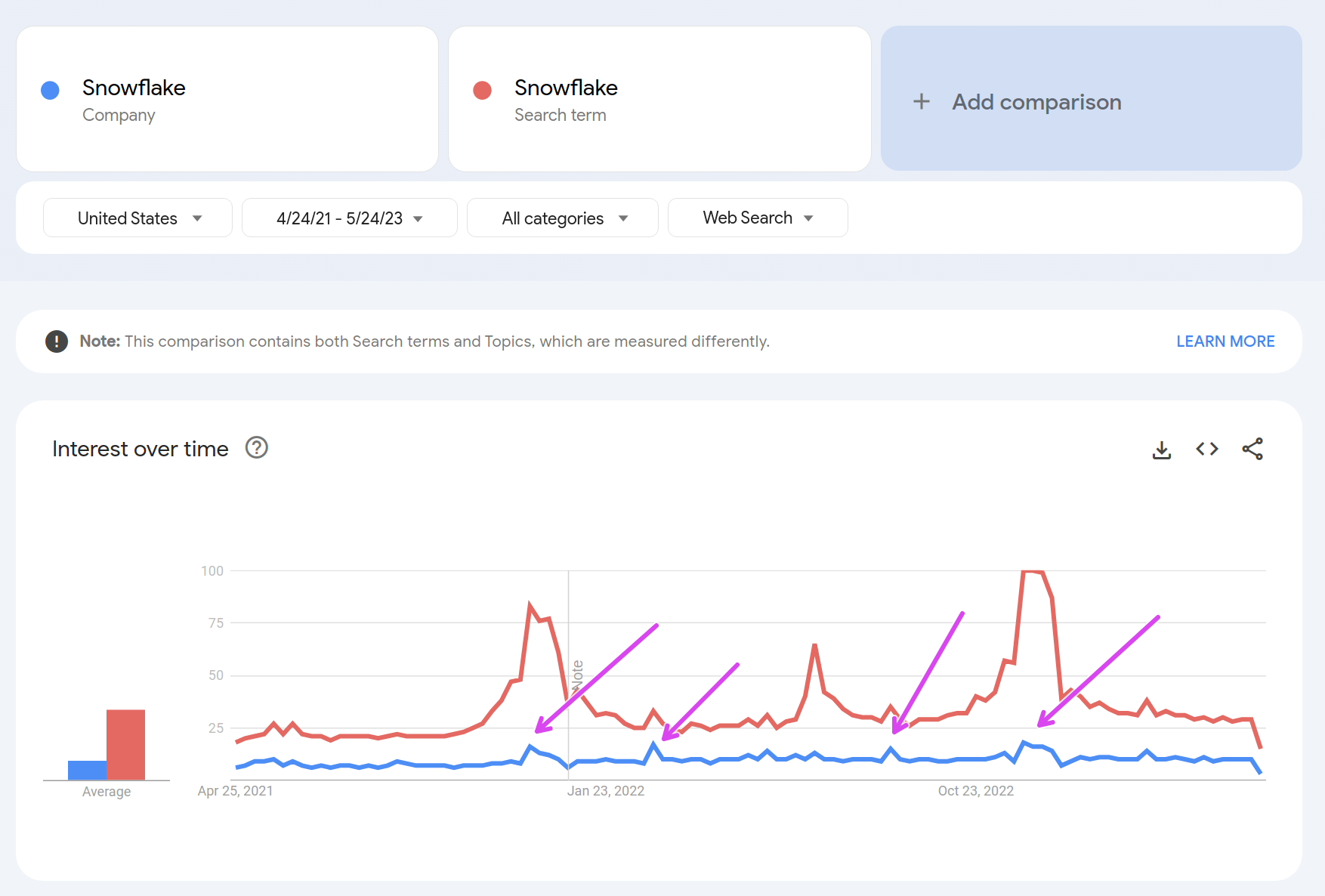
don't disagree with what you said, but your Google Trends argument has a big asterisk against it - right in the page it says "This comparison contains both Search terms and Topics, which are measured differently. LEARN MORE"
As a data point, if you examine something more granular and trend/topic tied, like Snowpark (which is close to Clickhouse alone) or "Snowflake Table" I would propose the overall point being made kind of stands.
The original term is ambiguous (I wish Snowflake had different branding) but more specific terms to Snowflake still rank high and are maybe less wonky of a comparison.
What's more expensive: the data engineering staff you need to have on hand to optimize data loading and queries all to make sure your Snowflake/Databricks bill doesn't balloon out of control, or the staff to maintain your data on either cloud or self-hosted Clickhouse for equal or better query performance?
In a world of limitless VC money, one might choose the more familiar and battle-tested Snowflake dynamics every time... but the world is shifting quite rapidly, and the degree to which investment in a Clickhouse stack is much less likely to "trap" you in rapidly expanding spend on a more closed ecosystem is becoming notable.
These are pretty different products with different use cases IME. I haven't used clickhouse in production but we use Snowflake extensively and I'm a big fan of the product and the business model. The ecosystem also seems to be in sync with the needs of people building on top of Snowflake as well.
They're both data warehouses that do a great job operating on massive datasets and neither should be your primary source of truth. I guess my question to you is: Why aren't they competitive products?
{kind=link}