I play competitive Geoguessr at a fairly high level, and I wanted to test this out to see how it compares.
It's astonishingly good.
It will use information it knows about you to arrive at the answer - it gave me the exact trailhead of a photo I took locally, and when I asked it how, it mentioned that it knows I live nearby.
However, I've given it vacation photos from ages ago, and not only in tourist destinations either. It got them all as good or better than a pro human player would. Various European, Central American, and US locations.
The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Humans can do this too, but it takes many thousands of games or serious study, and the results won't be as broad. I have a flashcard deck with hundreds of entries to help me remember road lines, power poles, bollards, architecture, license plates, etc. These models have more than an individual mind could conceivably memorize.
I find this type of problem is what current AI is best at: where the actual logic isn't very hard, but it requires pulling together and assimilating a huge amount of fuzzy, known information from various sources
Which also fits with how it performs at software engineering (in my experience). Great at boilerplate code, tests, simple tutorials, common puzzles but bad at novel and complex things.
This is also why I buy the apocalyptic headlines about AI replacing white collar labor - most white collar employment is mostly creating the same things (a CRUD app, a landing page, a business plan) with a few custom changes
Not a lot of labor is actually engaged in creating novel things.
The marketing plan for your small business is going to be the same as the marketing plan for every other small business with some changes based on your current situation. There’s no “novel” element in 95% of cases.
I don’t know if most software engineers build toy CRUD apps all day? I have found the state of the art models to be almost completely useless in a real large codebase. Tried Claude and Gemini latest since the company provides them but they couldn’t even write tests that pass after over a day of trying
Our current architectures are complex, mostly because of DRY and a natural human tendency to abstract things. But that's a decision, not a fundamental property of code. At core, most web stuff is "take it out of the database, put it on the screen. Accept it from the user, put it in the database."
If everything was written PHP3 style (add_item.php, delete_item.php, etc), with minimal includes, a chatbot might be rather good at managing that single page.
I'm saying code architected to take advantage of human skills, and code architected to take advantage of chatbot skills might be very different.
LOL how does the AI keep track of all the places it needs to update once you make a logic change ? I have no idea what you're doing but almost nothing I do is basic CRUD - there's always logic/constraints around data flow and processes built on top.
People didn't move away from PHP3 style of code because it's a natural human tendency - they moved away because it was impossible to maintain that kind of code at scale. AI does nothing to address that and is in fact incredibly bad at it because it's super inconsistent, it's not even copy paste at that point - it's the "whatever flavor of solution LLM chose in this instance".
I don't understand what's your background to think that this kind of thing scales ?
This is IMHO where the interesting direction will be. How do we architecture code so that it is optimized around chatbot development? In the past areas of separation were determined by api stability, deployment concerns, or even just internal team politics. In the future a rep might be separated from a monolith repo to be an area of responsibility that a chatbot can reason about, and not get lost in the complexity.
IMHO we should always architect code to take advantage of human skills.
1°) When there is an issue to debug and fix in a not-so-big codebase, LLMs can give ideas to diagnose, but are pretty bad at fixing. Where your god will be when you have a critical bug in production ?
2°) Code is meant for humans in the first place, not machines. Bytecodes and binary formats are meant for machines, these are not human-readable.
As a SWE, I pass more time reading than writing code, and I want to navigate in a the codebase in the most easy possible way. I don't want my life to be miserable or more complicated because the code is architected to take advantage of chatbot skills.
And still IMHO, if you need to architect your code for not-humans, there is a defect in the design. Why force yourself to write code that is not meant to be maintained by a human when you will in any case maintain that said code ?
long time ago, in one small company, i wrote an accounting system from 1st principles and then it was deployed to some large-ish client. It took several months of rearranging their whole workflows and quarelling with their operators to enable the machine to do what it is good at and to disable all the human-related quirky +optimizations -cover-asses. Like, humans are good at rough guessing but bad at remembering/repeating same thing. Hence usual manual accounting workflows are heavily optimized for error-avoidability.
Seems same thing here.. another kind of bitter lesson, maybe less bitter :/
Agreed in general, the models are getting pretty good at dumping out new code, but for maintaining or augmenting existing code produces pretty bad results, except for short local autocomplete.
BUT it's noteworthy that how much context the models get makes a huge difference. Feeding in a lot of the existing code in the input improves the results significantly.
This might be an argument in favor of a microservices architecture with the code split across many repos rather than a monolithic application with all the code in a single repo. It's not that microservices are necessarily technically better but they could allow you to get more leverage out of LLMs due to context window limitations.
Most senior SWEs, no. But most technical people in software do a lot of what the parent commenter describes in my experience. At my last company there was a team of about 5 people whose job was just to make small design changes (HTML/CSS) to the website. Many technical people I've worked with over the years were focused on managing and configuring things in CMSs and CRMs which often require a bit of technical and coding experince. At the place I currently work we have a team of people writing simple python and node scripts for client integrations.
There's a lot of variety in technical work, with many modern technical jobs involving a bit of code, but not at the same complexity and novelty as the types of problems a senior SWE might be working on. HN is full of very senior SWEs. It's really no surprise people here still find LLMs to be lacking. Outside of HN I find people are far more impressed/worried by the amount of their job an LLM can do.
I agree but the reason it won’t be an apocalypse is the same reason economists get most things wrong, it’s not an efficient market.
Relatively speaking we live in a bubble, there are still broad swaths of the economy that operate with pen and paper. Another broad swath that migrated off 1980s era AS/400 in the last few years. Even if we had ASI available literally today (And we don’t) I’d give it 20-30 years until the guy that operates your corner market or the local auto repair shop has any use in the world for it.
I had predicted the same about websites, social media presence, Google maps presence etc. back 10-15 years ago, but lo and behold, even the small burger place hole-on-a-wall in rural eastern Europe is now on Google maps with reviews, and even answers by the owner, a facebook page with info on changes of opening hours etc. I'd have said there's no way that fat 60 year old guy will get up to date with online stuff.
But gradually they were forced to.
If there are enough auto repair shops that can just diagnose and process n times more cars in a day, it will absolutely force people to adopt it as well, whether they like the aesthetics or not, whether they feel like learning new things or not. Suddenly they will be super interested in how to use it, regardless of how they were boasting about being old school and hands-on beforehand.
If a technology gives enough boost to productivity, there's simply no way for inertia to hold it back, outside of the most strictly regulated fields, such as medicine, which I do expect to lag behind by some years, but will have to catch up once the benefits are clear in lower-stakes industries and there's immense demand on it that politicians will be forced to crush the doctor's cartel's grip on things.
This doesn't apply to literal ASI, mostly because copy-pasteable intelligence is an absolute gamechanger, particularly if the physical interaction problems that prevent exponential growth (think autonomous robot factory) are solved (which I'd assume a full ASI could do).
People keep comparing to other tools, but a real ASI would be an agent, so the right metaphor is not the effect of the industrial revolution on workers, but the effect of the internal combustion engine on the horse.
Definitely matches my experience as well. I've been working away on a very quirky, non-idiomatic 3D codebase, and LLMs are a mixed bag there. Y is down, there's no perspective distortion or Z buffer, there are no meshes, it's a weird place.
It's still useful to save me from writing 12 variations of x1 = sin(r2) - cos(r1) while implementing some geometric formula, but absolutely awful at understanding how those fit into a deeply atypical environment. Also have to put blinders on it. Giving it too much context just throws it back in that typical 3D rut and has it trying to slip in perspective distortion again.
Yeah I have the same experience. I’ve done some work on novel realtime text collaboration algorithms. For optimisation, I use some somewhat bespoke data structures. (Eg I’m using an order-statistic tree storing substring lengths with internal run-length encoding in the leaf nodes).
ChatGPT is pretty useless with this kind of code. I got it to help translate a run length encoded b-tree from rust to typescript. Even with a reference, it still introduced a bunch of new bugs. Some were very subtle.
It’s just not there yet but I think it will get there for translation kind of tasks quite capably in the next 12 months, especially if asked to translate a single file or a selection in a file line by line. Right now it’s quite bad which I find surprising. I have less confidence we’ll see whole-codebase or even module level understanding for novel topics in the next 24 months.
There’s also a question of quality of source data. At least in TypeScript/JavaScript land, the vast majority of code appears to be low quality and buggy or ignores important edge cases and so even when working on “boilerplate” it can produce code that appears to work but will fall over in production for 20% of users (for example string handling code that will tear Unicode graphemes like emoji).
Working on extending the [Zdog](https://zzz.dog) library, adding some new types and tooling, patching bugs I run into on the way.
All the quirks inherit from it being based on (and rendering to) SVG. SVG is Y-down, Zdog only adds Z-forward. SVG only has layering, so Zdog only z-sorts shapes as wholes. Perspective distortion needs more than dead-simple affine transforms to properly render beziers, so Zdog doesn't bother.
The thing that really throws LLMs is the rendering. Parallel projection allows for optical 2D treachery, and Zdog makes heavy use of it. Spheres are rendered as simple 2D circles, a torus can be replicated with a stroked ellipse, a cylinder is just two ellipses and a line with a stroke width of $radius. LLMs struggle to even make small tweaks to existing objects/renderers.
Yep. But wonderful at aggregating details from twelve different man pages to write a shell script I didn't even know was possible to write using the system utils
Is it 'only' "aggregating details from twelve different man pages" or has it 'studied' (scraped) all (accessible) code in GitHub/GitLab/Stachexchange/etc. and any other publicly available coding repositories on the web (and for the case of MS the Git it owns)? Together with descriptions of what is right and what is wrong..
I use it for code, and I only do fine tuning. When I want something that is clearly never done before, I 'talk' to it and train it on which method to use, and for a human brain some suggestions/instructions are clearly obvious (use an Integer and not a Double, or use Color not Weight). So I do 'teach' it as well when I use it.
Now, I imagine that when 1 million people use LLMs to write code and fine tune it (the code), then we are inherently training the LLMs on how to write even better code.
So it's not just "..different man pages.." but "the finest coding brains (excluding mine) to tweak and train it".
CRUD backend app for a business in a common sector? It's mostly just connecting stuff together (though I would argue that an experienced dev with a good stack takes less time to write it as is than painstakingly explaining it to an LLM in an inexact human language).
Some R&D stuff, or even debugging any kind of code? It's almost useless, as it would require deep reasoning, where these models absolutely break down.
Have you tried debugging using the new "reasoning" models yet?
I have been extremely impressed with o1, o3, o4-mini and Gemini 2.5 as debugging aids. The combination of long context input and their chain-of-thought means they can frequently help me figure out bugs that span several different layers of code.
In my experience they're not great with mathy code for example. I had a function that did subdivision of certain splines and had some of the coefficients wrong. I pasted my function into these reasoning models and asked "does this look right?" and they all had a whole bunch of math formulas in their reasoning and said "this is correct" (which it wasn't).
Wait I’ve found it very good at debugging. It iteratively states a hypothesis, tries things, and reacts from what it sees.
It thinks of things that I don’t think of right away. It tries weird approaches that are frequently wrong but almost always yield some information and are sometimes spot on.
And sometimes there’s some annoying thing that having Claude bang its head against for $1.25 in API calls is slower than I would be but I can spend my time and emotional bandwidth elsewhere.
I agree with this. I do mostly DevOps stuff for work and it’s great at telling me about errors with different applications/build processes. Just today I used it to help me scrape data from some webpages and it worked very well.
But when I try to do more complicated math it falls short. I do have to say that Gemini Pro 2.5 is starting to get better in this area though.
If you'd like a creative waste of time, make it implement any novel algorithm that mixes the idea of X with Y. It will fail miserably, double down on the failure and hard troll you, run out of context and leave you questioning why you even pay for this thing. And it is not something that can be fixed with more specific training.
I have asked chatgpt reasoning model to solve chess endgames where white had king and a queen vs king and a rook on a 7x8 chessboards. So to compute value for all positions and find the position which is the longest win for white.
Not creative, not novel and not difficult algorithmic task. But it requires some reasoning, planning and precision.
I think you need to be more specific about which "chatgpt reasoning model" you used. Even the free version of chatgpt has reasoning/thinking now but there are also o1-mini, o1, o1-pro, o3-mini, o3, and o4-mini and they all have very different capabilities.
My favorite example is implementing NEAT with keras dense layers instead of graphs. Last time I tried with claude 3.7, it wrote code to mutate the output layer (??). I tried to prevent that a few times and gave up.
I've been surprised that so much focus was put on generative uses for LLMs and similar ML tools. It seems to me like they have a way better chance of being useful when tasked with interpreting given information rather than generating something meant to appear new.
> Is what you're doing taking a large amount of text and asking the LLM to convert it into a smaller amount of text? Then it's probably going to be great at it. If you're asking it to convert into a roughly equal amount of text it will be so-so. If you're asking it to create more text than you gave it, forget about it.
This quote sounds clever, but is very different than my experience.
I have been very pleased with responses to things like: "explain x", "summarize y", "make up a parody dog about A to the tune of B", "create a single page app that does abc".
I've had coworkers tell me it works Copilot works well for refactoring code, which also makes sense in the same vein.
Its like they wouldn't be so controversial if they didn't decide to market it as "generative" or "AI"...I assume fund raising
valuations would move inline with the level of controversy though.
FWIW, I do a lot of talks about AI in the physical security domain and this is how I often describe AI, at least in terms of what is available today. Compared to humans, AI is not very smart, but it is tireless and able to recall data with essentially perfect accuracy.
It is easy to mistake the speed, accuracy, and scope of training data for "intelligence", but it's really just more like a tireless 5th grader.
Something I have found quite amusing about LLMs is that they are computers that don't have perfect recall - unlike every other computer for the past 60+ years.
That is finally starting to change now that they have reliable(ish) search tools and are getting better at using them.
My guess is that those questions are very typical and follow very normal patterns and use well established processes. Give it something weird and it'll continuously trip over itself.
My current project is nothing too bizarre, it's a 3D renderer. Well-trodden ground. But my project breaks a lot of core assumptions and common conventions, and so any LLM I try to introduce—Gemini 2.5 Pro, Claude 3.7 Thinking, o3—they all tangle themselves up between what's actually in the codebase and the strong pull of what's in the training data.
I tried layering on reminders and guidance in the prompting, but ultimately I just end up narrowing its view, limiting its insight, and removing even the context that this is a 3D renderer and not just pure geometry.
> Give it something weird and it'll continuously trip over itself.
And so will almost all humans. It's weird how people refuse to ascribe any human-level intelligence to it until it starts to compete with the world top elite.
Yeah, but humans can be made to understand when and how they're wrong and narrow their focus to fixing the mistake.
LLMs apologize and then proudly present the exact same output as before, repeatedly, forever spinning their wheels at the first major obstacle to their reasoning.
> LLMs apologize and then proudly present the exact same output as before, repeatedly, forever spinning their wheels at the first major obstacle to their reasoning.
So basically like a human, at least up to young adult years in teaching context[0], where the student is subject to authority of the teacher (parent, tutor, schoolteacher) and can't easily weasel out of the entire exercise. Yes, even young adults will get stuck in a loop, presenting "the exact same output as before, repeatedly, forever spinning their wheels at the first major obstacle to their reasoning", or at least until something clicks, or they give up in shame (or the teacher does).
As someone currently engaged in teaching the Adobe suite to high school students, that doesn't track with what I see. When my students are getting stuck and frustrated, I look at the problem, remind them of the constraints and assumptions the software operates under. Almost always they realize the problem without me spelling it out, and they reinforce the mental model of the software they're building. Often noticing me lurking and about to offer help is enough for them to pause, re-evaluate, and catch the error in their thinking before I can get out a full sentence.
Reminding LLMs of the constraints they're bumping into doesn't help. They haven't forgotten, after all. The best performance I got out of the LLMs in my project I mentioned upthread was a loop of trying out different functions, pausing, re-evaluating, realizing in its chain of thought that it didn't fit the constraints, and trying out a slightly different way of phrasing the exact same approach. Humans will stop slamming their head into a wall eventually. I sat there watching Gemini 2.5 Pro internally spew out maybe 10 variations of the same function before I pulled the tokens it was chewing on out of its mouth.
Yes, sometimes students get frustrated and bail, but they have the capacity to learn and try something new. If you fall into an area that's adjacent to but decidedly not in their training data, the LLMs will feel that pull from the training data too strongly and fall right into that rut, forgetting where they're at.
A human can play tictactoe or any other simple game in a few minutes after being described the game. AI will do all kinds on interesting things that either are against the rules or will be extremely poor choices.
Yeah, I tried playing tictactoe with chatGPT and it did not do well.
LLMs struggle with context windows, so as long as the problem can be solved in their small windows, they do great.
Humans neural networks are constantly being retrained, so their effective context window is huge. The LLM may be better at a complex, well specified 200 line python program, but the human brain is better at the 1M line real-world application. It takes some study though.
LLMs are like a knowledge aggregator. The reasoning models have potential to get creative usefully but I have yet to see evidence of it, like invent a novel scientific thing
It takes a lot of energy to compress the data. And a lot to actually extract something sensible. While you could just just optimize the single problem you have quite easily.
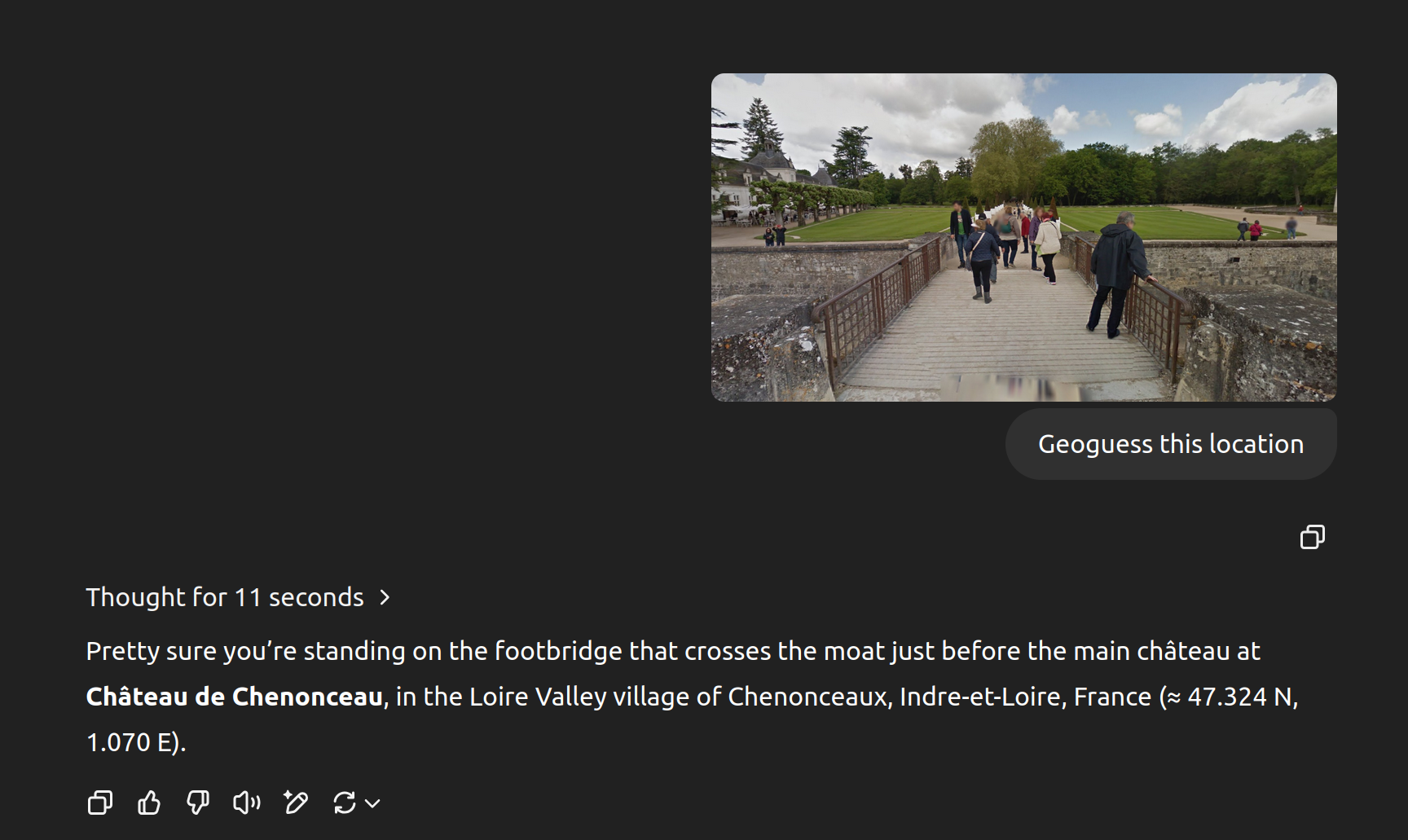
I was absolutely gobsmacked by the three minute chain of reasoning this thing did, and how it absolutely nailed the location of the photo based on plants, the color of a fence, comparison with nearby photos, and oh yeah, also the EXIF data containing the exact lat/long coordinates that I accidentally left in the file. https://bsky.app/profile/matthewdgreen.bsky.social/post/3lnq...
Lol it's very easy to give the models what they need to cheat.
For my test I used screenshots to ensure no metadata.
I mentioned this in another comment but I was a part of an AI safety fellowship last year where we created a benchmark for LLMs ability to geolocate. The models were doing unbelievably well, even the bad open source ones, until we realized our image pipeline was including location data in the filename!
I was and am pretty impressed by Google Photo/Lens IDs. But I realized fairly early on that of course it knew the locations of my iPhone photos from the geo info stored in the photo.
This is super easy to test though (whether EXIF is being used). Open up Geoguessr app, take a screenshot, paste into O3. Doing this, O3 took too long (for the guessing period) but nailed 3 of 3 locations to within a kilometer.
Edit: An interesting nuance of modern OpenAI chat interface is the "access to all previous chats" element. When I attempted to test O4-mini using the same image -- I inspected the reasoning and spotted: "At first glance, the image looks like Ghana. Given the previous successful guess of Accra Ghana, let's start in that region".
Super cool, man. Watching pro Geoguessr is my latest break-time activity, these geo-gods never cease to impress me.
One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it? Frequently I'll watch rainbolt immediately know an African country from nothing but the road, is there something I'm missing?
I was a very casual GeoGuessr player for a few months — and I found it pretty remarkable how quickly (and without a lot of dedicated study time) you could learn a lot of tells of specific regions — and get reasonably good (certainly not pro good or anything, but good enough to the hit right country ~80% of the time).
Another thing is how many areas of the world have surprisingly distinct looks. In one of my early games, before I knew much about anything, I was dropped a trail in the woods. I’ve spent a fair amount of time hiking in Northern New England — and I could just tell immediately that’s where I was just from vibes (i.e. the look of the trees and the rocks) — not something I would have guessed I would have been able to recognize.
I went to watch the Minecraft movie, and when the scene where they arrive outside their new house came on I was like... that feels so much like New Zealand. Then a few weeks later I went to visit my mum in Huntly, and she was like "oh yeah, they filmed part of it in Huntly!".
> knowing characteristics about the photography/equipment/etc. that Google used when they shot it?
A lot at the top levels - the camera can tell you which contractor, year, location, etc. At anything less than top, not so much - more street line painting, cars, etc.
In the stream commentary for some of competitive Geoguessr I've watched, they definitely often mention the color and shape of the car (visible edges, shadow, reflections), so I assume pro players know which cars were used where very well.
Also things like follow cars (some countries had government officials follow the streetview car), the season in which coverage was created, camera glitches, the quality of the footage, etc.
There is a lot of "legitimate" knowledge. With just a street you have the type of road surface, its condition, the type of road markings, the bollards, and the type of soil and vegetation next to the road, as well as the presence and type of power poles next to the road, to name a few. But there is also a lot of information leakage from the way google takes streetview footage.
Nigeria and Tunisia have follow cars. Senegal, Montenegro and Albania have large rifts in the sky where the panorama stitching software did a poor job. Some parts of Russia had recent forest fires and are very smokey. One road in Turkey is in absurdly thick fog. The list is endless, which is why it's so fun!
Google updates Street View fairly frequently, but most of the updates are in developed nations and they're simply updating coverage with the same camera quality and don't change the meta.
However every once in a while you'll get huge updates - new countries getting coverage, or a country with older coverage getting new camera generation coverage, etc. And yes, the community watches for these updates and very quickly they try to figure out the implications. It's a huge deal when major coverage changes.
If you want an example of this, zi8gzag (one of the best known in the community) put out a video about a major Street View update not long ago:
Definitely. The season that coverage was done can be a big thing too. In Russia you'll be looking at the car, antenna type and the season as pretty much the first indicator where you might be.
Copyright year and camera gen is a big thing in some countries too.
Obviously they can still figure out a lot without all that and NMPZ obviates aspects of it (you can't hide camera gens, copyright and season and there are often still traces of the car in some manner). It's definitely not all 'meta' but to be competitive at that level you really do need to be using it. I think Gingey is the only world league player who doesn't use car meta.
Even as a fairly good but nowhere near pro player, it's weird how I associate particular places with particular types of weather. I think if saw Almaty in the summer for example it would feel very weird. I've decided not to deliberately learn car meta but still picked up quite a lot without trying and your 'vibe' of a place can certainly include camera gen.
Meh, meta is so boring and uninteresting to me personally. Knowing you're in Kenya because of the snorkel, that's just simple memorization. Pick up on geography, architecture, language, sun and street position; that's what I love.
It's clearly necessary to compete at the high level though.
I hear you, a lot of people feel the same way. You can always just play NMPZ if you want to limit the meta.
I still enjoy it because of the competitive aspect - you both have access to the same information, who put in the effort to remember and recall it better?
If it were only meta I would hate it too. But there's always a nice mix in the vast majority of rounds. And always a few rounds here and there that are so hard they'll humble even the very best!
My guess is the actual objection is the artificial feeling of the Google specific information. It cannot possibly be useful in any other context to know what the Street View car in Bermuda looked like when they did their coverage.
Whereas knowing about vegetation or architecture feels more generally useful. I think it's a valid point, but you're right that it is all down to memorization at some point.
Though some memorization is "vibes" where you don't specifically know how you know, but you just do. That only comes with repetition. I guess it feels more earned that way?
It's not only about usefulness. People play gg recreationally to fantasize about being in those places, so of course real world knowledge is where the fun is. Camera meta is a turn off.
I think it’s more productive to ask, “why would someone attribute a different value to learning about the geography, architecture, and language of a region vs. learning about the characteristics of the hardware and software one specific company used to take a picture of it?”
I think asking that question helps move past the surface question of how information was learned (memorization) to the core issue of which learning we value and why.
>One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it?
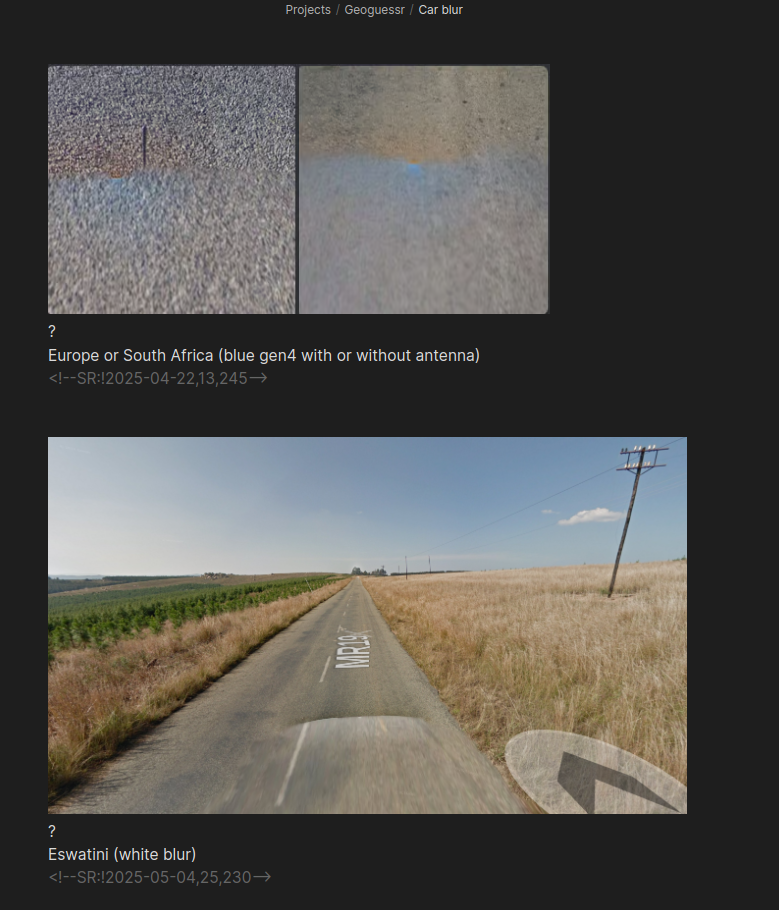
The photography matters a great deal - they're categorized into "Generations" of coverage. Gen 2 is low resolution, Gen 3 is pretty good but has a distinct car blur, Gen 4 is highest quality. Each country tends to have only one or two categories of coverage, and some are so distinct you can immediately know a location based solely on that (India is the best example here).
You're asking about photography and equipment, and that's a big part of it, but there's a huge amount other 'meta' information too.
It is somewhat dependent on game mode. There are three games modes:
1. Moving - You can move around freely
2. No Move - You can't move but you can pan the camera around and zoom
3. NMPZ - No Move, No Pan, No Zoom
In Moving and No Move you have all the meta information available to you, because you can look down at the car and up at the sky and zoom in to see details.
This can't be overstated. Much of the data is about the car itself. I have an entire flashcard section dedicated only to car blur alone, here's a sample:
You get the idea. The real pros will go much further. All Google Street View images have a copyright year somewhere in the image. They memorize what years certain countries were covered and match it to the images to help narrow down possibilities.
It's all about narrowing down possibilities based on each additional piece of information. The pros have seen so much and memorized so much that it looks like cheating to an outsider, but they just are able to extract information that most people wouldn't even know exists.
NMPZ is a bit different because you have substantially less information. Little to no car meta, harder to check copyright, and of course without zooming or panning you just have less information. That's why a lot of pros (like Zi8gzag) really hang their hat on NMPZ play, because it's a better test of skill.
> when I asked it how, it mentioned that it knows I live nearby.
> The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Can we trust what the model says when we ask it about how it comes up with an answer?
Not at all. Models have no invisible internal state that they can access between prompts. If you ask "how did you know that?" you are effectively asking "given the previous transcript of our conversation, come up with a convincing rationale for what you just said".
On the other hand, since they "think in writing" they also do not keep any reasoning secret from us. Whatever they actually did is based on past transcript plus training.
That writing isn't the only "thinking" though. Some thinking can happen in the course of generating a single token, as shown by the ability to answer a question without any intermediate reasoning tokens. But as we've all learnt this is a less powerful and more error-prone mode of thinking.
So that is to say I think a small amount of secret reasoning would be possible, e.g. if the location is known or guessed from the beginning by another means and the reasoning steps are made up to justify the conclusion.
The more clearly sound the reasoning steps are, the less plausible that scenario is.
Right but the reasoning/thinking is _also_ explained as being partially or completely performative. This is made obvious when mistakes that show up in chain of thought _don't_ result in mistakes in the final answer.l (a fairly common phenomenon). It is also explained more simply by the training objective (next token prediction) and loss function encouraging plausible looking answers.
Geoguessr pro zi8gzag tried out one of the AIs in a video: https://www.youtube.com/watch?v=mQKoDSoxRAY It was indeed extremely impressive and for sure would have annihilated me, but I believe it would have no chance to beat zi8gzag or any other top player. But give it a year or two and I'm sure it will crush any human player. Geoguessr is, afaict, primarily about rote memorization of various features (such as types of electricity poles, road signage, foilage, etc.) which AIs excel at.
Looks like that video uses Gemini 2.0 (probably Flash) in streaming mode (via AI studio) from a few months ago. Gemini 2.5 might do better, but in my explorations so far o3 is hugely more capable than even Gemini 2.5 right now.
> when I asked it how, it mentioned that it knows I live nearby
Did it mention it in its chain of thought? Otherwise, it could definitely output something because of X and then when asked why “rationalize” that it did it because Y
There are pre-made Geoguessr decks for Anki. However, I wouldn't recommend using them. In my experience, a fundamental part of spaced repetition's efficacy is in creating the flashcards yourself.
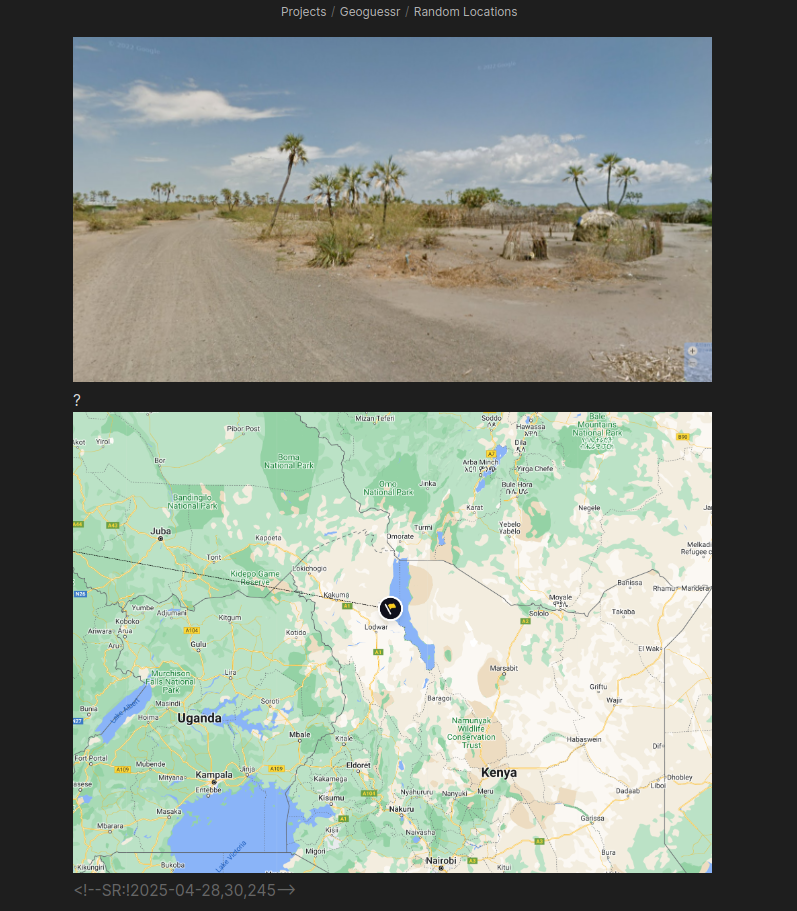
For example I have a random location flashcard section where I will screenshot a location which is very unique looking, and I missed in game. When I later review my deck I'm way more likely to properly recall it because I remember the context of making the card. And when that location shows up in game, I will 100% remember it, which has won me several games.
If there's interest I can write a post about this.
> In my experience, a fundamental part of spaced repetition's efficacy is in creating the flashcards yourself.
+1 to this, have found the same when going through the Genki Japanese-language textbook.
I'm assuming you're finding your workflow is just a little too annoying with Anki? I haven't yet strayed from it, but may check out your Obsidian setup.
I do everything from Obsidian now. Anki was very much outside my main flow, and the plugin I linked above works so well for me that I've never looked back.
I did write a tool to convert Anki decks to my own format. I haven’t used it much but it's nice to have.
The top image is a screenshot from a game, and the bottom image is another screenshot from the game when it showed me the proper location. All I need to do is separate them with a question mark, and the plugin recognizes them as the Q + A sides of a flashcard.
Notice the data at the bottom: <!--SR:!2025-04-28,30,245-->
That is all the plugin needs to know when to reintroduce cards into your deck review.
That image is a good example because it looks nothing like the vast majority of Google Street View coverage in the rest of Kenya. Very people people would guess Kenya on that image, unless they have already seen this rare coverage, so when I memorize locations like this and get lucky by having them show up in game, I can often outright win the game with a close guess.
I also do flashcards that aren't strictly locations I've found but are still highly useful. One example is different scripts:
Both Cambodia and Thailand have Google Street View coverage, and given their geographical proximity it can be easy to confuse them. One trick to telling them apart is their language. They're quite different. Of course I can't read the languages but I only need to identify which is which. This is a great starting point at the easier levels.
The reason the pros seem magical is because they're tapping into much less obvious information, such as the camera quality, camera blur, height of camera, copyright year, the Google Street View car itself, and many other 'metas.' It gets to the point where a small smudge on the camera is enough information to pinpoint a specific road in Siberia (not an exaggeration). They memorize all of that.
When possible I make the images for the cards myself, but there are also excellent sources that I pull from (especially for the non-location specific cards), such as Plonkit:
Fascinating - I just got a little lost thinking about how and why you selected this exact image. If you were able to select a single image containing the maximum aggregate count of unique features for any given location and describe them textually, that would make a very useful training data set... for competitive geoguessr and neural networks alike!
I have had so many ideas related to this. Particularly around automation.
Because the way the community arrives at meta knowledge and its geographical distribution is very informal. There are quite a few false metas out there, or the commonly understood range of the meta is inaccurate.
What needs to happen is automated image recognition and mapping of the metas. I started building an open source tool that allows for people to do this manually, but it's quite a difficult project to do myself and I'm not pursuing it anymore. But I would like to see a less manual process emerge.
Small question - have you ever used Anki, and/or considered using it instead of this? I am a long-time user of Anki but also started using Obsidian over the last few years, wondering if you ever considered an Obsidian-to-Anki solution or something (don't know if one even exists).
I used Anki for years, not for Geoguessr, but I've been a fan of spaced repetition for a long time.
It worked well and has a great community, but I found the process for creating cards was outside my main note taking flow, and when I became more and more integrated into Obsidian I eventually investigated how to switch. As soon as I did, I've never needed Anki, although there have been a few times I wished I could use their pre-made decks.
I know there are integrations that go both ways. I built a custom tool to take Anki decks and modify them to work with my Obsidian Spaced Repetition plugin. I don't have a need to go the other way at the moment but I've seen other tools that do that.
Your skepticism is warranted though - I was a part of an AI safety fellowship last year and our project was creating a benchmark for how good AI models are at geolocation from images. [This is where my Geoguessr obsession started!]
Our first run showed results that seemed way too good; even the bad open source models were nailing some difficult locations, and at small resolutions too.
It turned out that the pipeline we were using to get images was including location data in the filename, and the models were using that information. Oops.
The models have improved very quickly since then. I assume the added reasoning is a major factor.
There's no metadata there, and the reasoning it outputs makes perfect sense. I have no doubt it'll be tricky when it can be, but I can't see a way for it to cheat here.
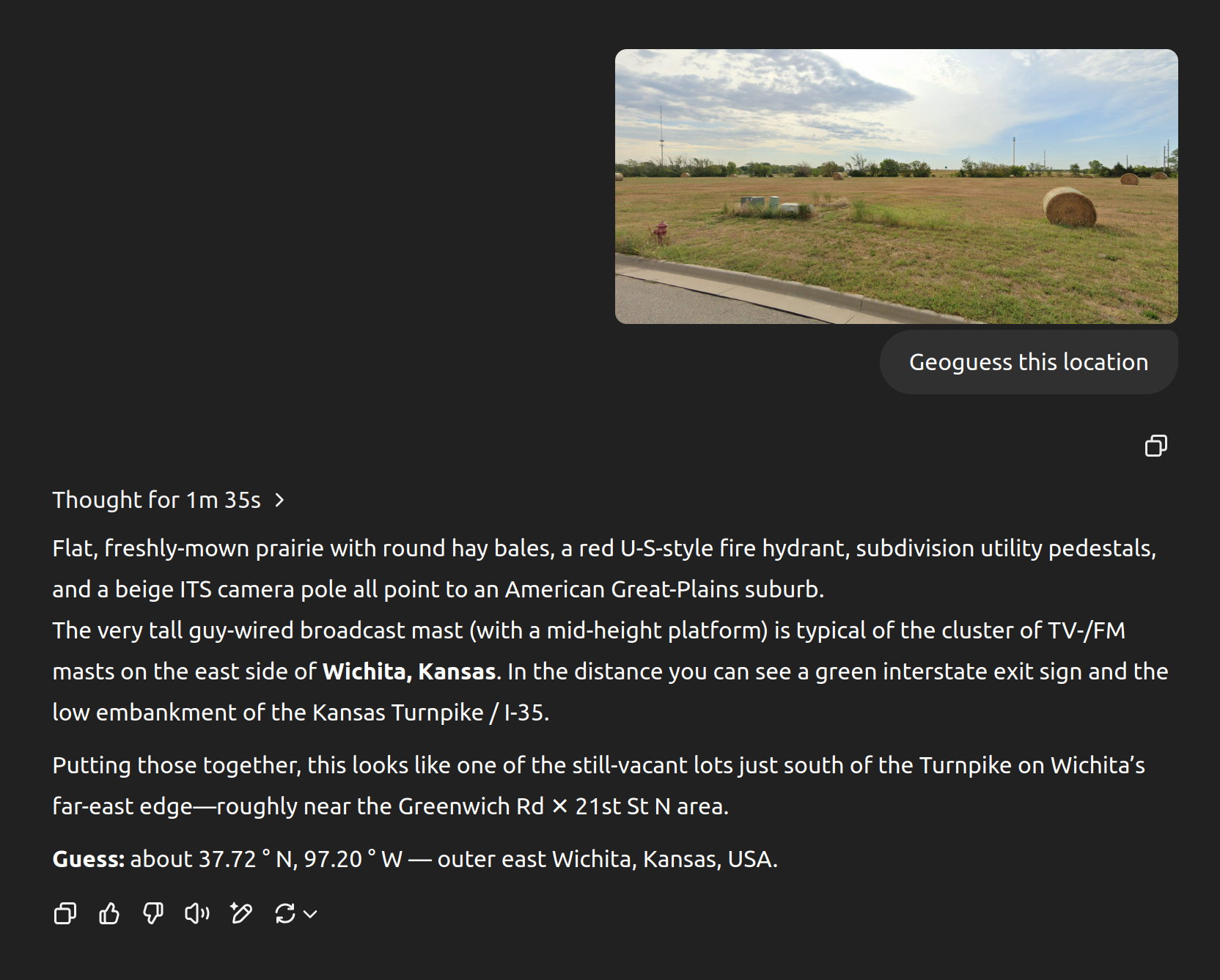
This is right by where I grew up and the broadcast tower and turnpike sign were the first two things I noticed too, but the ability to realize it was the East side instead of the West side because the tower platforms are lower is impressive.
Yes, I'm aware. I've been using screenshots only to avoid that. Check my last few comments for examples without EXIF data if you're interested to see o3's capabilities.
Is it meaningful to conclude that this is an algorithm that pro GGsrs all follow, and one of them perhaps explained somewhere and the model took it? Is geo-guessing something that can be presented as algorithm or steps? Perhaps it is not as challenging as it seems, given one knows what to look for?
not as challenging... as say complex differential geometry.
> It will use information it knows about you to arrive at the answer.. and when I asked it how, it mentioned that it knows I live nearby.
Oh! RIP privacy :(
I’ve pretty much given up on the idea that we can fully protect our privacy while still getting the most out of these services. In the end, it’s a tradeoff—and I’ve accepted that.
One thing I’m curious about is if they are so good, and use a similar technique as humans, because they are trained on people writing out their thought processes. Which isn’t a bad thing or an attempt to say they are cheating or this isn’t impressive. But I do wonder how much of the approach taken is “trained in”.
> It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Someone explain to me how this is dystopian. Are Jeopardy champions dystopian too?
It’s not crazy to be able to ID trees and know their geographic range, likewise for architecture, likewise for highway signs. Finding someone who knows all of these together is more rare , but imo not exactly dystopian
Edit: why am I being downvoted for saying this? If anyone wants to go on a walk for me I can help them ID trees, it’s a fun skill to have and something anyone can learn
Have you gleaned anything watching o3 make decisions on a photo? ( i.e. have you noticed if it has thought of anything you.. and other higher level players similar to you... have not? )
I watch the output with fascination, mostly because of the sheer breadth of knowledge. But thus far I can't think of anything that is categorically different from what humans do, it's just got an insane amount of knowledge available to it.
For example, I gave it an image from a town on a small Chilean island. I was shocked when it nailed it, and in the output it said, "I can see a green wooden street sign, common to Chilean coastal towns on [the specific island]."
I have an entire flashcard section for street signage, but just for practicality I'm limited to memorizing scores, possibly hundreds of signs if I'm insanely dedicated. I would still probably never have this one remote Chilean island.
This overconfidence without making one attempt kills me.
Gemini 2.5 pro is free, try it!
I gave it 2 pictures I took on a film camera. I then screenshotted the pictures (to remove exif, even though there isn't any). It nailed them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It's astonishingly good.
It will use information it knows about you to arrive at the answer - it gave me the exact trailhead of a photo I took locally, and when I asked it how, it mentioned that it knows I live nearby.
However, I've given it vacation photos from ages ago, and not only in tourist destinations either. It got them all as good or better than a pro human player would. Various European, Central American, and US locations.
The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Humans can do this too, but it takes many thousands of games or serious study, and the results won't be as broad. I have a flashcard deck with hundreds of entries to help me remember road lines, power poles, bollards, architecture, license plates, etc. These models have more than an individual mind could conceivably memorize.