This is computer vision, an I'm somewhat an expert in the area. I can tell that video sequence recognition is _much_ harder problem than image recognition.
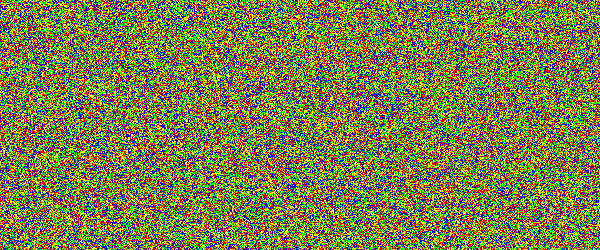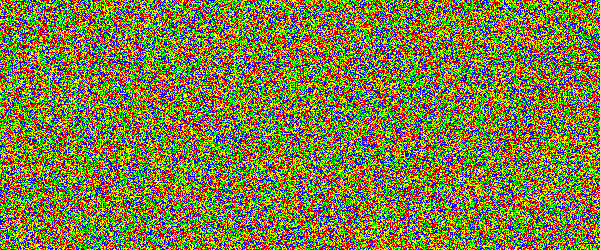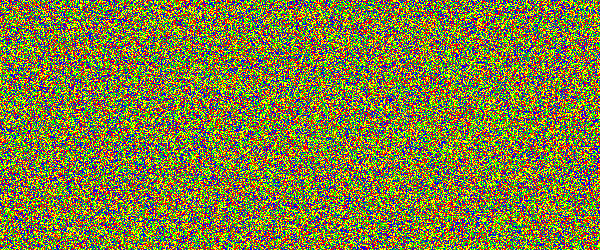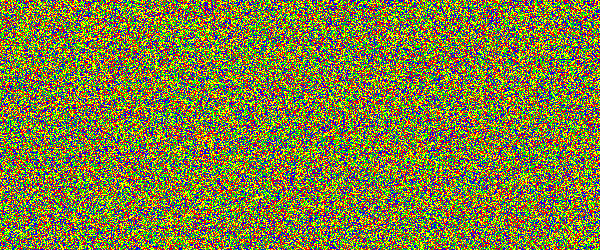
For example, if you would show an letter made out of random noise moving through random noise, current computer vision algorithms would not be able to recognize anything. And you would pick out that letter immediately. Human visual subsystem is really amazing in that sense.
Oh. I remember reading some vision paper and in the supplement materials there've been a couple of videos with letters moving. Doubt, I'll be able to find it that easily.
Should be relatively easy to code with any library that can draw a text on a bitmap. Like PIL, matplotlib, etc. Use ffmpeg to make a video out of frames.
1. draw letters (just black/white) masks;
2. fill letters with noise;
4. fill background with noise;
5. copy letters using a mask onto background, using X,Y as loc;
6. add a little bit of new noise to letters;
8. modify X,Y coordinates (move letters SLIGHTLY);
9. go to step 4.
I made a proof-of-concept implementation and, well, it works, but I suspect they're too difficult for many people. They can be made easier by emphasizing one of the colors in the letters, but that opens them up to more traditional attacks.
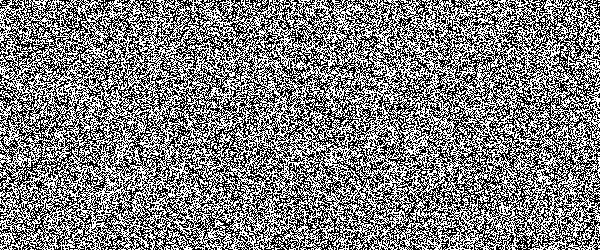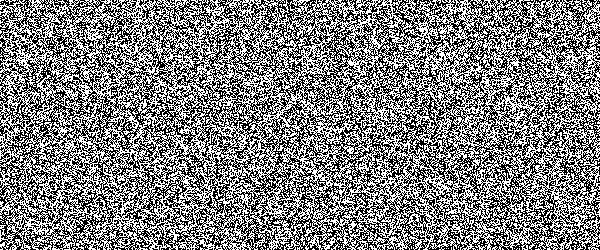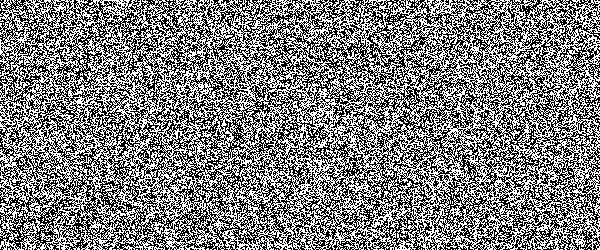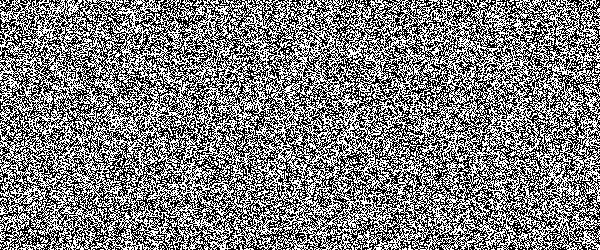{kind=link}
{kind=link}
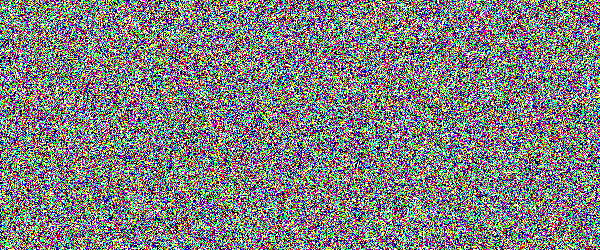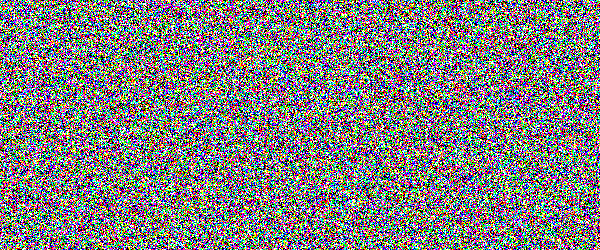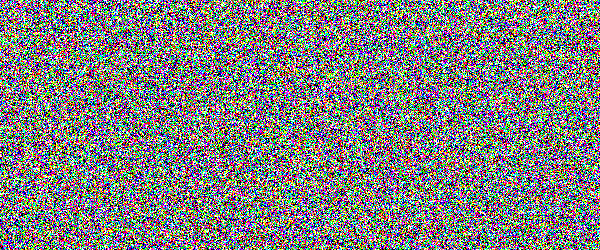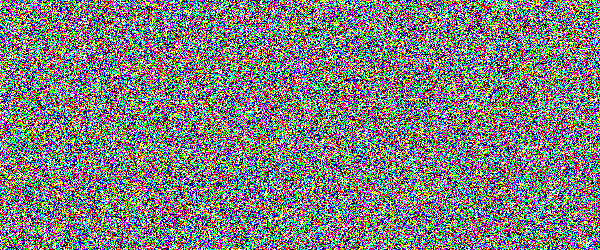{kind=link}
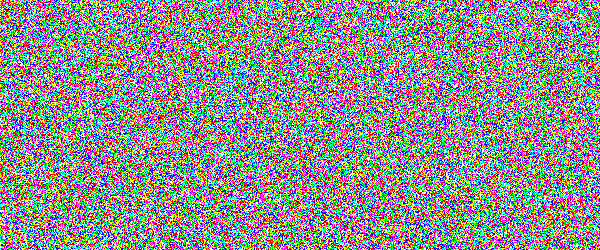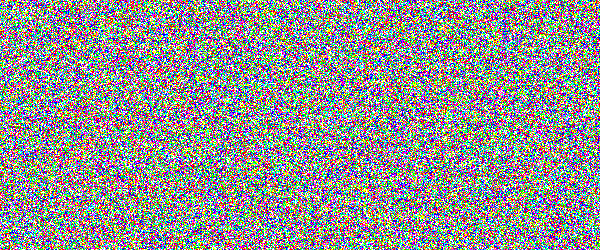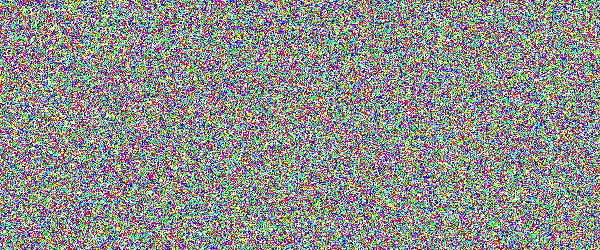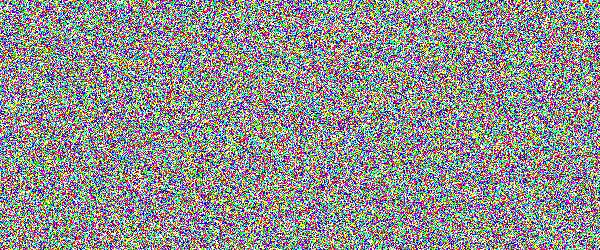{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
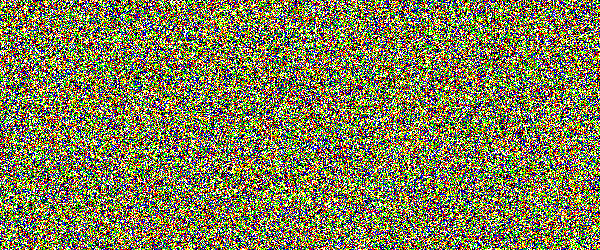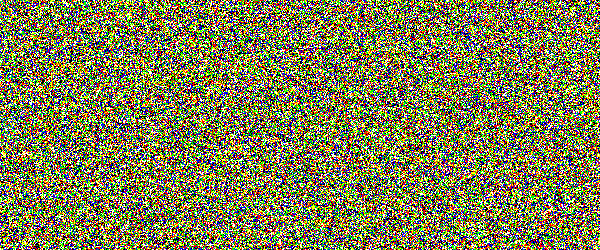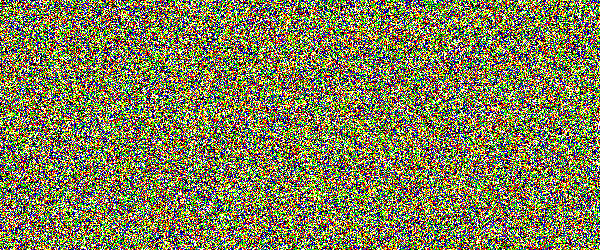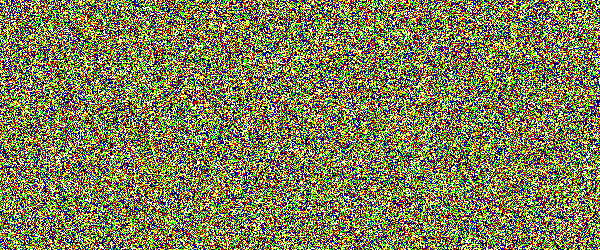{kind=link}
{kind=link}
{kind=link}
{kind=link}
For example, if you would show an letter made out of random noise moving through random noise, current computer vision algorithms would not be able to recognize anything. And you would pick out that letter immediately. Human visual subsystem is really amazing in that sense.