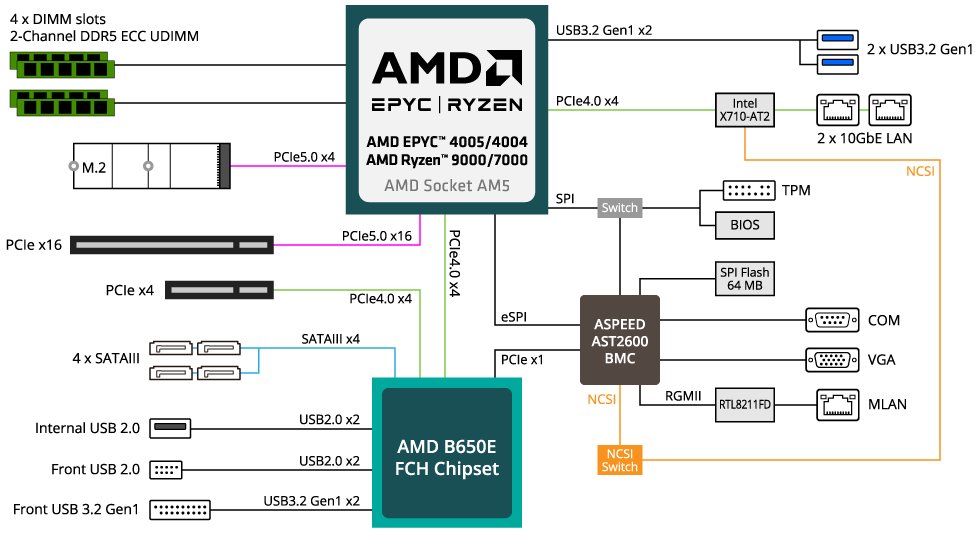
crypto mining only needs 1 PCIe lane per GPU, so you can fit 24+ GPUs on a standard consumer CPU motherboard (24-32 lanes depending on the CPU). Apparently ML workloads require more interconnect bandwidth when doing parallel compute, so each card in this demo system uses 16 lanes, and therefore requires 1.) full size slots, and 2.) epyc[0] or xeon based systems with 128 lanes (or at least greater than 32 lanes).
per 1 above crypto "boards" have lots of x1 (or x4) slots, the really short PCIe slots. You then use a riser that uses USB3 cables to go to a full size slot on a small board, with power connectors on it. If your board only has x8 or x16 slots (the full size slot) you can buy a breakout PCIe board that splits that into four slots, using 4 USB-3 cables, again, to boards with full size slots and power connectors. These are different than the PCIe riser boards you can buy for use with cases that allow the GPUs to be placed vertically rather than horizontally, as those have full x16 "fabric" that interconnect between the riser and the board with the x16 slot on them.
[0] i didn't read the article because i'm not planning on buying a threadripper (48-64+ lanes) or an epyc (96-128 lanes?) just to run AI workloads when i could just rent them for the kind of usage i do.
i used to use this one when i had all (three of my) nvme -> 4x sata boardlets and therefore could not fit a GPU in a PCIe slot due to the cabling mess.
Crypto mining could make use of lots of GPUs in a single cheap system precisely because it did not need any significant PCIe bandwidth, and would not have benefited at all from p2p DMA. Anything that does benefit from using p2p DMA is unsuitable for running with just one PCIe lane per GPU.
PCIe P2P still has to go up to a central hub thing and back because PCIe is not a bus. That central hub thing is made by very few players(most famously PLX Technologies) and it costs a lot.
PCIe p2p transactions that end up routed through the CPU's PCIe root complex still have performance advantages over split transactions using the CPU's DRAM as an intermediate buffer. Separate PCIe switches are not necessary except when the CPU doesn't support routing p2p transactions, which IIRC was not a problem on anything more mainstream than IBM POWER.
Maybe not strictly necessary, but a separate PCIe backplane just for P2P bandwidth bypasses topology and bottleneck mess[1][2] of PC platform altogether and might be useful. I suspect this was the original premise for NVLink too.
{kind=link}
{kind=link}