The decrease of Github activity might be caused by their 2FA rollout. Everything that does not have a 2FA workflow (like a git mirror bot) got locked out from non-public repositories this summer.
Seems reasonable. If this is the case, we shouldn’t see a decline from summer (post lockout) to now. In fact we should see an uptick in the next period as more people get around to unlocking their accounts (or at least not a further decline).
Lol. I'm not going to "unlock" my accounts.
GIthub/Microsoft don't have a monopoly
on hosting code.There are better alternatives that
don't suddenly force their users to jump through hoops.
Hope they introduce face-to-face verification via Zoom
so the even the loyal MS-lemmings feel a sting.
> The advent and rise of AI-based code assistants are already impacting the data that populates RedMonk’s language rankings.
Not only that, they are impacting the actual languages people use. Why use some new / esoteric language that an LLM doesn't know much about, when you can get the same job done much faster using a language that the LLM knows well and can debug?
It's going to get increasingly difficult to bootstrap new languages unless they are available in LLMs.
I've actually been building toy languages for fun (nothing I'm ready to share) with GitHub Copilot as an aid, and it's able to pick up on my homegrown language just fine. It helps that I opted for C-style syntax, but it's able to pick up on semantic concepts like effects that don't exist in the mainstream, as well as specific syntactic choices like `:` vs `=` for record constructors.
Where a new language will be severely disadvantaged is in the blank page problem. With a well-known language you can start a new project with just a comment and let Copilot get you over the initial barrier of just having something down on the page. A new language won't work because it needs a fair amount of context before it's able to produce correct code.
I deeply disagree with this. With Good Old Fashioned Dev Tools like Zero TurnAround, ReSharper, PyCharm, Clang tools, etc. the tool was specific to the language stack. Esoteric languages would simply not have many tools. All the LLM-based tool needs is to hoover up some code on GitHub, or even just your other project files as context, and it will start generating useful stuff. On top of that, translating between languages just became a whole lot easier.
What other project files or GitHub code? It’s a new language. And what does “hoover up” mean? Use the context window for language basics? RAG? Retrain the model?
Also the LLM won’t have been trained on the vast corpus of debugging sessions, blog posts, etc of existing languages. I’d expect the quality to be very poor compared to the current top players.
(It’s effectively the same phenomenon as folks sticking to languages with a big hiring pool.)
Using something like e.g. Zig right now is already slower because examples are limited, a barrage of common questions over the last decade don't exist on a Stack Overflow type site, few people are experts in it, and the tooling/ecosystem is immature. Is replacing part of this with an LLM really impacting anything or just continuing what was already true before?
I wonder if this can be turned into an advantage however. Say the development team invests time into writing really good documentation and examples and then feeds it into LLMs and posts a link to a chat bot on their documentation. Much easier and faster for that bot to answer the inevitable 1000s of easy questions than waiting around for the community to do so.
I've seen this. I can get quite a bit of decent responses from LLMs about Python. But using it for Elixir produces more shady/dated answers. And Jetpack Compose, it just completely gets weird (and mostly worthless, being either too synthetically approximated or dated).
It really illustrates (to me) that LLMs are "Plausibility Machines". They produce plausible answers. Plausibility is informed by repeated observability over large sets. We asses something as plausible when it matches the majority of our observations. That's how the parlor trick of seeming to "tell the truth" is pulled off. The venn overlap of "plausible" and "true" is pretty high. But when "truth" is in flux, you start to see the feet of the wizard behind the curtain.
That's weird. Which ones are you trying? I get great elixir help out of CGPT4. Sure, it needs close supervision - you can't just trust it and you need to actually understand everything it suggests, and it loves to "forget" things you told it just a moment ago about how you can't use a guard clause there, or whatever - but in terms of just getting a decent starting point, man, it's been a game-changer. The $20 I send OpenAI each month is the most no-brainer money I spend.
It was definitely pretty bad with liveview for a while, while that was under heavy development and API changes, but it's had a data update that mostly fixes that, and if you specify the version it's helpful there too.
Copilot stuff has made some things harder for me to review, funnily enough. I don't blame it on the model, but the programmer using it with zero scrutiny.
If people doggedly continue down that path they're going to stagnate for as long as they assume the AI is always right.
Just because an LLM can can cobble together some output doesn't mean that the output is instantly trustworthy.
Not to mention languages often optimise for different things. If you want to default to JS for everything because the AI can auto-complete that more easily, you're locking into a very specific operating model.
At what point does the language become a useless abstraction, and AI becomes the new “language”?
I’m a software developer yet still amazed at how many layers of abstraction are tolerated in user space.
Take web development. You’d think at some point the stack of a half dozen frameworks would be abandoned in favor of vanilla JavaScript. But the house of cards continues to grow.
So maybe languages will still stick around when they are no longer the human interface.
What is HN's obsession with JS frameworks? There's 4 big ones (React, Vue, Angular, Ember (arguable if Ember still counts)) that have been in use for the better part of 2 decades at this point. Sure there's plenty of smaller ones like Svelte cropping up, but most places just use one of these 4 for the most part.
Anyone who's ever tried to build anything big with vanilla JS knows why these frameworks exist in the first place. The ones like Vue or Svelte aren't even really that complex to grok anyways, despite all the hyperbole about them.
But hopefully my point still stands. A coder writes instructions for the computer; it amazes me the tolerance for having those instructions go through multiple layers of transformations (sometimes even multiple layers of languages) before hitting the OS.
If the point of a scripting language is to provide a user experience not attainable by a lower-level compiled language (which in turn is not attainable by machine code), wouldn't AI nullify the benefits of both the scripting and the lower-level languages?
I would think ColdFusion (CFML) would be esoteric, but recently I was tasked to work on an ancient CFML code base for a few days and Copilot saved my bacon. I was frankly astonished at how well it knew CFML. It was like a mind reader. I'd write <cfset some_var =... and it would fill in about 15 lines of code that were exactly what I needed to have happen. How did it do so well at such an esoteric language?
From my intuition (and experience) with LLMs, they make more of what is in the context. If you use a language that is often used for business CRUD software, the assistant will be great it giving you business CRUD software, of typical business CRUD software quality. Using copilot for work, my experience is that it will happily offer ugly but context-plausible solutions (that often don't even work), but if you stop and ask "maybe there's a better way to do this", it often will suggest good simplifications. Especially if you give it a hint ("Maybe it's worth trying...")
I haven't really used copilot with, say, Rust or Haskell, but if the average quality of code is better in those languages, maybe it will take less coaxing to actually suggest good code?
Either way, LLMs are great at generalizing between human languages, so I expect they transfer a lot between programming languages too. I think your language has to be pretty weird for copilot to not get a grip on it with enough context.
I had someone submit a C++ code review where AI was used to write the code. It looked like C++98: new and delete all over, even though modern c++ is 12 years old by now. There are a lot of other things that scream I learned to program C++ in 1997 and see no reason to update my skills to anything newer. Modern C++ is really a different language and yet there is a lot of not modern code out there that AIs don't know is bad.
It's not that they don't know it's bad, it's that fundamentally, they're not trying to help you. They're trying to match a probability distribution. And if there's lot of 1997-quality C++ code out there (there is!), that's highly likely what you're going to get.
If you provide high quality context, it's more likely to produce high quality code too - but it can also spiral into creating bad code if it accidentally starts off on the wrong foot. The more bad code you have, the more bad code it suggests. That's why I think it's very important to clean up the code it suggests, even if it's just cosmetically.
Unsurprising as StackOverflow has exactly the same problem.
There are lots of answers that are flat out wrong 5+ years after they were answered. There is no way to go back and "unmark" that answer.
> Modern C++ is really a different language and yet there is a lot of not modern code out there that AIs don't know is bad.
This is a human problem and why I won't use C++ anymore. Instead of "modern C++" we needed a new language to replace C++ and leave the old nastiness behind. We'll see if any of the new replacements like Carbon get any traction.
> Not only that, they are impacting the actual languages people use. Why use some new / esoteric language that an LLM doesn't know much about, when you can get the same job done much faster using a language that the LLM knows well and can debug?
Hmm, I can see it going the opposite way - maybe the availability of LLMs means that having an active user community in your timezone is less important, and makes semi-obscure languages more competitive.
It depends. Usually there’s other things like thorough documentation, bug fixes, and comprehensive libraries that accompany popular languages. And LLM support is basically only as good as the documentation and online resources.
For me, GPT4 means Rust is approachable, something I would never have considered a couple years ago. There’s tons of documentation online, but it’s great to be able to get the “vocabulary” of my question from GPT4 before looking it up online. Rust compiler errors are pretty good, but a LLM really smooths over the rough spots.
> Not only that, they are impacting the actual languages people use. Why use some new / esoteric language that an LLM doesn't know much about, when you can get the same job done much faster using a language that the LLM knows well and can debug?
I don't see how this is anything new. Similar tension has always existed slowing adoption of new technology. I've resisted picking up new languages because I could implement something faster/better in languages I already know. I've been skeptical about some because the ecosystem just isn't there yet. You said "a language that the LLM knows well and can debug" when sometimes the resistance is that the new language does have as good of tooling/debugging support.
There is nothing new here and if anything LLMs could help. I've noticed the community seems pretty understanding/accepting of low quality outputs of some of these LLMs. The small corpus of a new/esoteric would mean even lower quality, but I don't think that'd be a deal breaker for some folks.
LLMs can barely generate legal code, so they're certainly unable to debug them or write the test cases completely without expert guidance of someone who knows what the hell they're doing.
It will take 10 to 20 years before there is "Star Trek computer"-level of self-programming, agent-based systems.
Prognostication is an inexact, bullshit guestimate that you can't hope to improve upon except to claim you have special or greater Dunning-Kruger "knowledge".
Not just that. When the general public uses LLMs more, this will calcify markets for Everything. Try bootstrapping any new product, store, idea, art - you name it.
Perhaps. Not exactly evidence but I see this on drudge today: https://www.wsj.com/tech/ai/news-publishers-see-googles-ai-s.... I like your response though, funny! I find myself checking the dates of articles to see if it’s before ChatGPT. And I find myself responding less online because I don’t know if a human is on the other side. Calcification of human communication, is the biggest threat. I … think … you are human though!
It is not just a pure RAG index, it is having enough source material and tutorials to draw upon such that "best practices" for a given library or toolset get encoded into the model.
I've seen a couple companies offer a RAG enabled ChatGPT for their SDK, but without a large number of stack overflow and medium posts detailing how to use the SDK in different scenarios, well, there isn't much help an LLM can offer that I cannot just get from whatever is on a company's site.
Back in the day Microsoft used to pay boat loads of money to have absurdly complex sample applications shipped alongside new libraries and SDKs. The sample apps were often fully featured end to end solutions that had been gone over by testers as well.
The idea being, since there wasn't any really good online help back then (aside from news groups and such, which were useful if you knew about them), you had to rely on sample code or on books, books which Microsoft also commissioned to be written.
Maybe someday we'll get back to that point, companies paying money for large volumes of sample code to be written, but this time with the goal of having it ingested by LLMs.
Copilot was key for me for learning Rust. The syntax is verbose and unique enough that it was hard to get into from nothing without constant syntax errors. Copilot eliminated that barrier: I could describe what I wanted in a comment and immediately see a (relatively) idiomatic way to do it in Rust.
Because it was an anecdote directly relevant to the comment it replied to, which happened to be someone using Rust?
Would you have replied the same way had they mentioned the ability to use LLMs to generate Python? Would you equally imply an accusation of a Python developer of being a shill for mentioning it?
Curious if the layoffs factor in to the decline in a statistically significant way? I wouldn’t expect that to account for all of the changes but maybe that accounts for some.
Even if you aren't explicitly targeting people who's primary job is that some still likely get laid off. Sheer numbers alone could lead to real damage there.
On the other hand, if I were laid off, I'd pretty quickly clean up my open source profile and get to creating some cool open source packages to showcase my work.
Though my intuition tells me that the net effect of layoffs is still negative.
If you were coding because that's your passion, yeah. I'll bet a number of the people laid off (as happened after the dot-com crash) decided that this was the sign they should go and get a career they actually enjoyed.
Shopify as an example is heavily involved in open source (mostly Rails) and had large layoffs. I wouldn't be surprised if many of the contributors were gone dark.
> the data [...] showed a roughly 25% decline in pull requests in 1H2023 as compared to 2H2022 PRs [...] largely lacking an explanation
May be obvious, but would rather know if you saw PRs-per-repo decline. Otherwise, I wonder if some very frequent-PR repos (automated or otherwise) had previously skewed numbers. Also curious if early numbers for this half can be obtained/compared.
This reminds me of the time managers tried to judge developer productivity based on lines of code changed. The person who ran the build script to generate the minified output for production kept winning. Mgmt was like why is this person generating 10x what you all do. #rockstardevelopers
Github activity is an abstruse source of programming activity. I might do many github actions or few, separate from the actual use of the language. A lot of activity when learning is probably using online websites and online environments. People can move to other systems, use git on their own for instance.
They need another datasource. There's another classic not reliable system, survey programmers to see what they are using.
Oh, this made me connect some dots. At first I figured increase in GitHub activity during the pandemic was because people were home more and had more time to contribute to open source.
But a lot of people took that time to learn software development. And a lot of courses will have you publish your learning projects to GitHub as a way to learn version control and processes (and also to promulgate awareness of, and analyze their course since there's often templates involved).
Often this is just creating repos and pushing them, and since TFA directly looks at pull requests, perhaps this isn't it, unless these courses regularly include lessons on how to do a pull request (perhaps from yourself to your own repo).
If that was a significant factor, it would make sense why the activity is down.
I feel like many, myself included, have moved away from using GitHub after they turned the good will of opensource into copilot. Trampling licenses and reselling open solutions to companies just doesn't sit right with many people. I will not feed the beast.
This is especially tough for RedMonk's rankings because they typically evaluate languages on "lifetime summary" metrics like total number of tags on Stack Overflow, or total number of projects on GitHub. e.g.:
If Stack Overflow becomes more and more a reflection of "historical behavior" rather than "modern behavior", this sort of metric will become a less useful way to judge modern developer usage.
If attention shifts a bit to other languages (Nim? Zig? D? Clojure? Kotlin?), or if the answer is already in the multitude of answered questions, the activity will drop too. Or a multitude of not directly obvious other reasons.
> There are languages that were under- or over-represented by using public GitHub repos; there are communities that were under- or over-represented by looking at discussions happening in Stack Overflow.
I'm not sure I understand. Granted, they're never going to get perfect data about language rankings. But, why would AI assistants affect the rankings of language in a way that makes their methodology more unsound? They mention a drop-off in SO tag usage, and in Github pull requests: that's an indication of something, but is there any reason to believe it distorts the results so as to give undue prominence to one language more than another?
Intuitively, I can't think of how. "Undue" is the keyword: even if the prominence changed as a result of AI language assistants, wouldn't that be an indication that people are just using those languages more, with the help of AI assistants?
I'm really just wondering why, given the unavoidable squishiness of the methodology, the decrease in magnitude would bother them so much. They probably don't see their work as fundamentally hand-wavey, and maybe I just do, and that's the problem. I guess they're just investigating it, but the results seem to be more or less what you'd expect to conclude ab initio. I could be wrong, often am.
I imagine they're just trying not to tell the wrong story just because of a tangential change in how developers use these tools, so taking some time to look closely and account for things and provide the necessary context for the report is sensible. I guess it's just taking longer than they expected due to the unexpected GitHub changes.
Lets say you are tracking lion populations. You watch a couple of watering holes and count the number of lions. From there you use stats to make estimates of total number of lions in the world. Suddenly your data shows a drop of 30% and is continuing to decline. Are lions going extinct, or did they find a new watering hole? If they found a new watering hole then you need to change your measuring locations to account for the shift.
I don't think software development has started slowing down. So the data is indicating that the way they were measuring is becoming less useful than it was, and that they will need to find new data sources if they are going to continue.
If that really is AI, maybe Copilot and friends will become an interesting source of data on programming language use.
ChatGPT can only provide answers for programming languages and libraries that were included in its training. Granted, unpopular programming languages have online activity, too, but sample size matters.
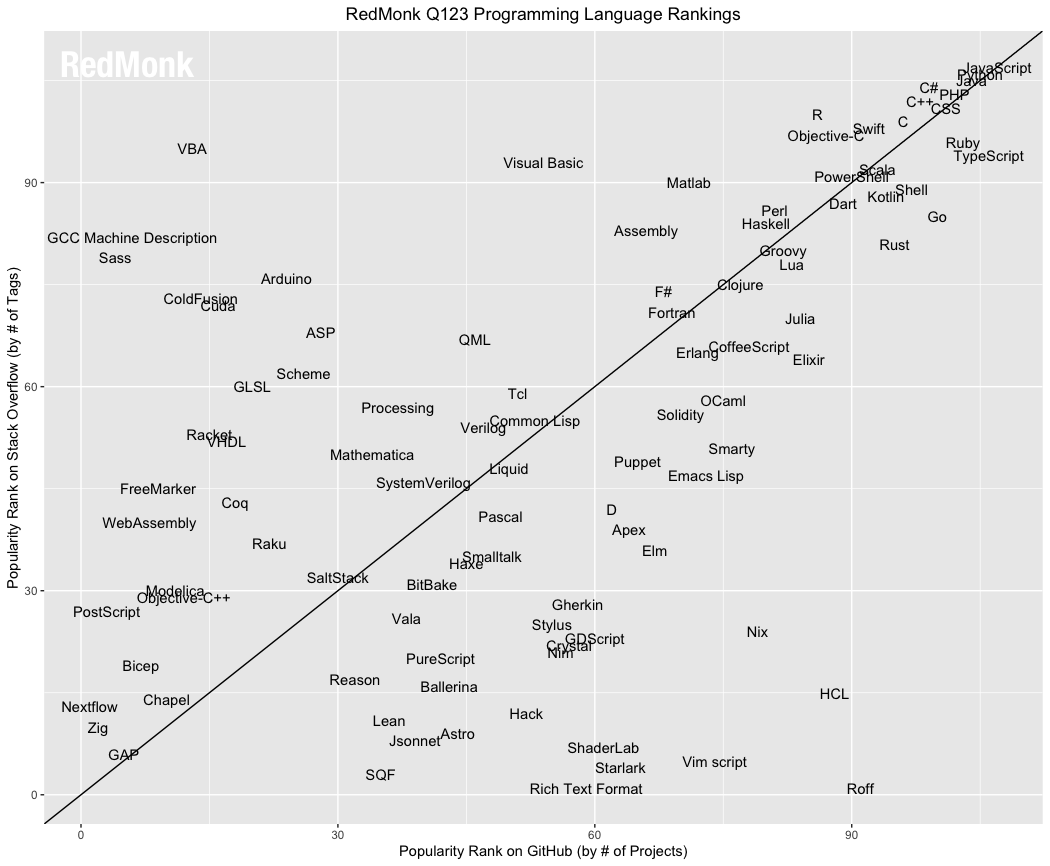
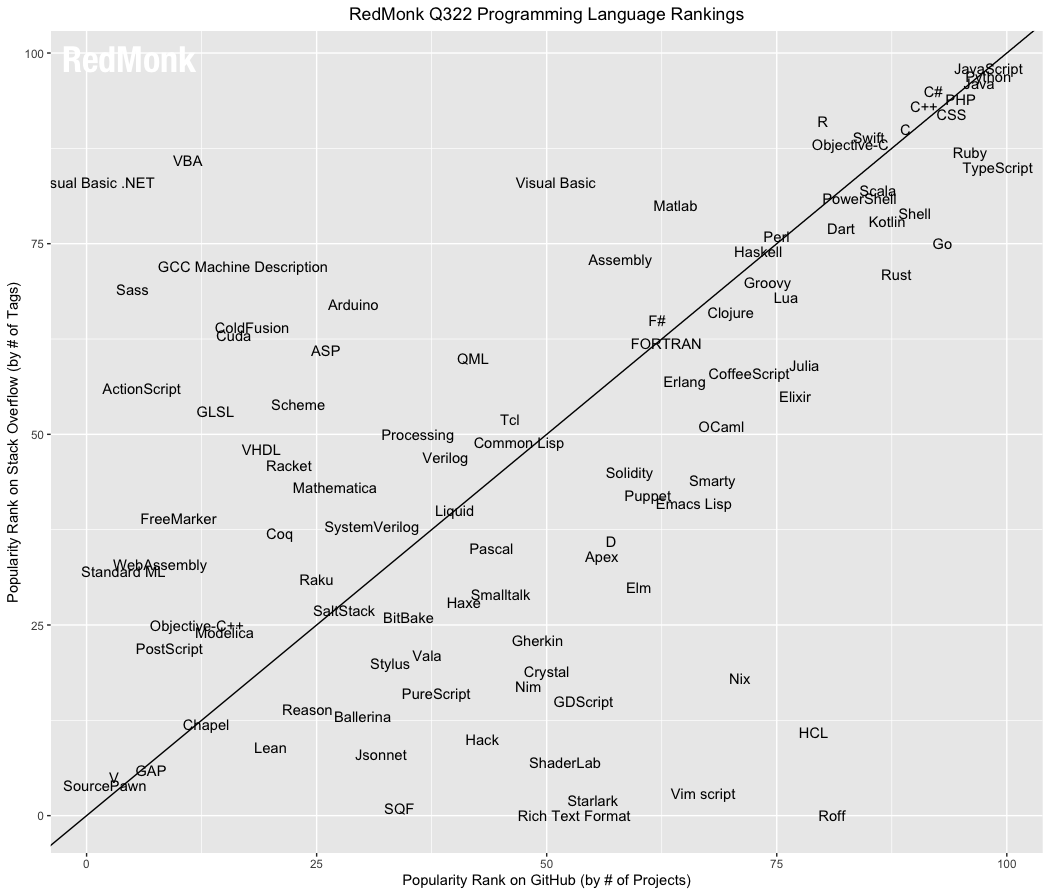
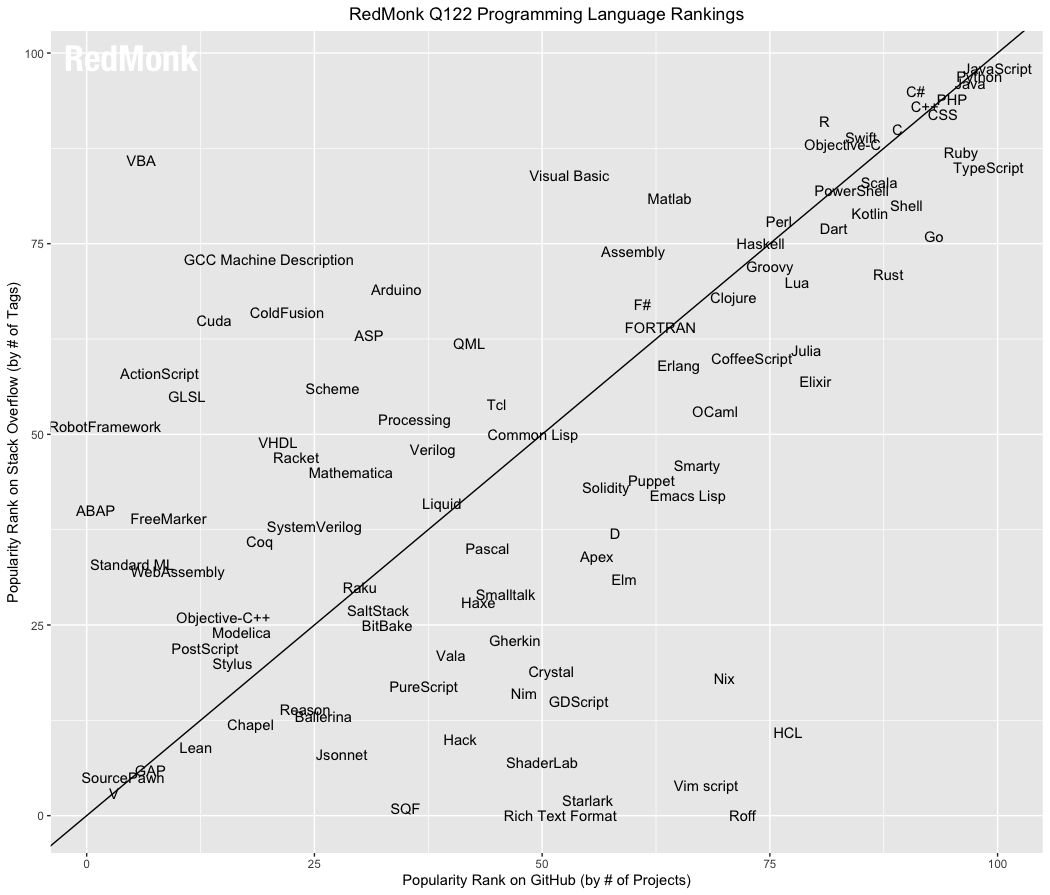
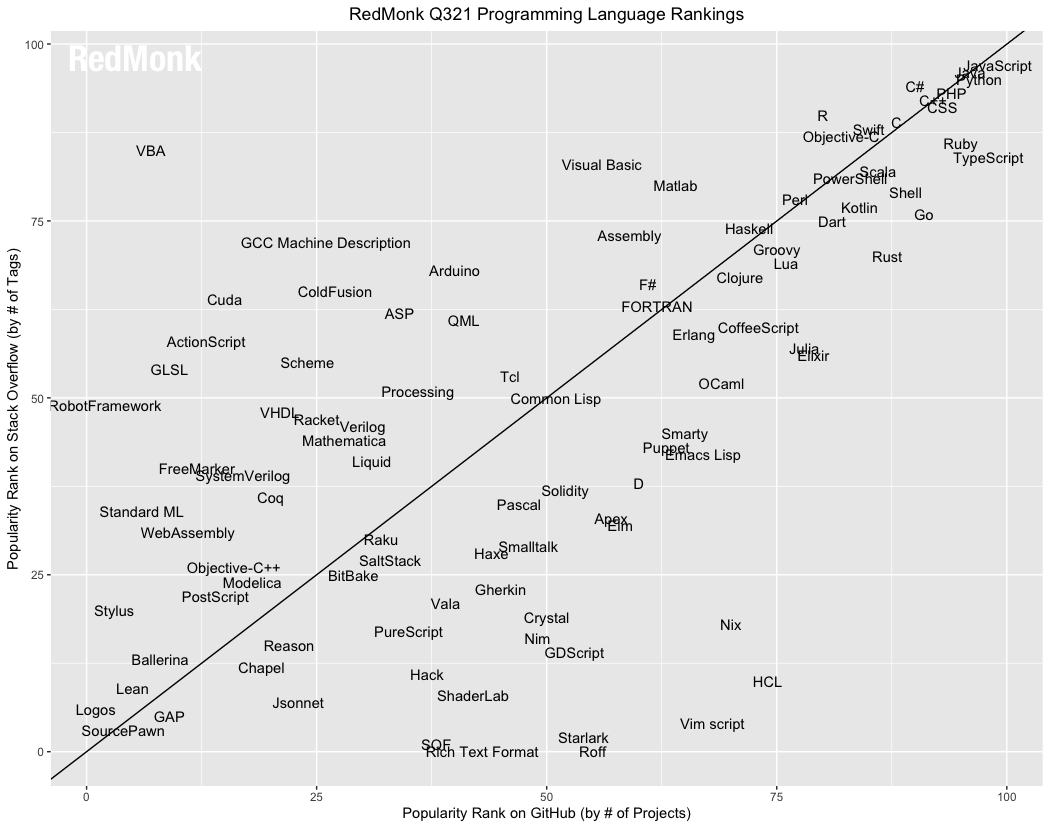
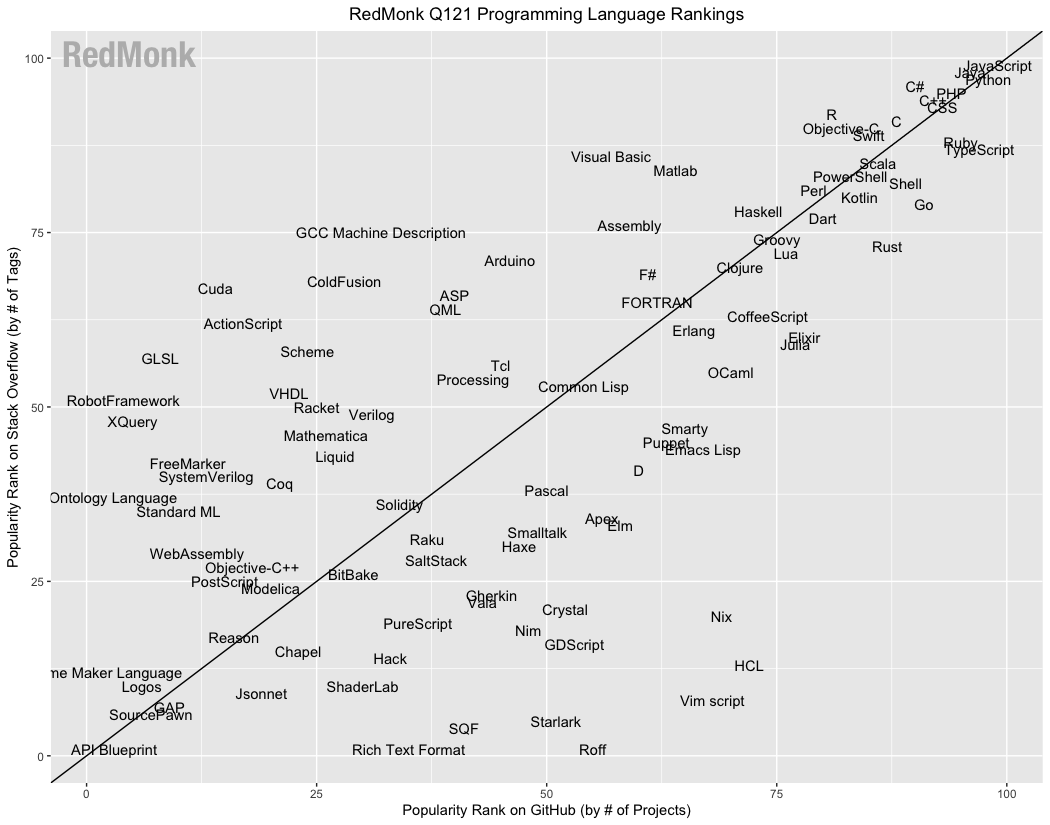
Just to see what it looked like, plotted the last 5 seasons of top language from RedMonk on the StackExchange / Github plot. Mostly ad hoc circling of language groups to get an idea of movement patterns. Kept changing their chart scaling and naming every season... [1]
If I could make a friendly suggestion, I think the data would be a bit easier to interpret if it were a grouped bar chart (GH rank, SO rank) and sorted by one (or the sum of the reciprocals).
You're probably aware, but that's a totally different ranking. On RedMonk's last ranking, TypeScript was one of the most popular languages, D was maybe 55% as popular, and Prolog didn't even make the list.
RedMonk and many other language rankings have methodological issues when languages are very similar. Many people tag TypeScript questions as JavaScript, repositories with large amounts of JS checked in are considered JavaScript even if they have complete TypeScript typings (see: Webpack), and so-on.
I think this is one of the strongest signals that TypeScript is the dominant way JavaScript is written:
The type definitions for React are more popular than React itself. Why is that? Even users who aren't choosing to use using TypeScript are benefiting from their IDE installing typings on their behalf, at a rate large enough to exceed the CI/CD systems and users running "npm/yarn/pnpm install" and only installing "react".
It's like this for other packages as well; but the sheer popularity of react makes the point well. Many, many developers are using TypeScript even if indirectly, it's what makes their IDE light up.
Let me explirant/elucidate those who may not understand why TIOBE is a dumb signal:
The primary "problem" programming language ranking lists solves are: 0. the amelioration of trepidation of the novice as to which tool in the toolbox to "select" without first building something by trial-and-error. 1. The businesses who don't want to know anything but wish to surf fashionable trends in business and technology.
TS is a strict superset of JS. It probably doesn't get as much credit for being safer and superior to JS because it's routinely transpiled out of existence and doesn't offer language features on its own besides gradual, static typing. And there aren't many questions about it because its fairly self-explanatory. The biggest problem with TS is the Cambrian explosion of confusion of procedural configuration files (.ts and .js).
Prolog is used in programming language courses to solve logic brain teasers, formal verification every now and then (although Coq, Isabelle, RedPRL, and Idris exist now) and some niches like TerminusDB and Watson. It was probably used once to solve a formal proof and then modeled by Erlang. It's one of those influential languages amongst language designers like ALGOL 68, Haskell, and LISP that weren't themselves popular. (You can thank ALGOL 68 for the Bourne shell family.)
The other thing is programming language popularity peeing contests are rarely useful because what is practical is productivity and correctness at scale under the financial and effort constraints in reality for a given problem, team, and codebase. Plus, thundering herds of people just in it for the money tend to have resumes that all look the same and completely lack curiosity. Also, recruiters who follow popularity are the ones I can righteously tell to go hell for insulting me by saying things like "X isn't going anywhere" (In one case: X was Go, and t was 2011). While there is "safety in numbers", there are N ways to trim hairy cattle. Sometimes, easier and better ways come along that need to be tried. Curiosity and learning never go out of style except at shops that are dinosaurs marching to the tar pits. Shops that discourage learning in favor of ship-ship-ship yesterday, avoid bettering their employees, and are full of people who have no technical side-hobbies lack engineering craftspeople.
I can definitely see why StackOverflow is suffering. Why would you ask questions there, when 98% of the time your question will be duped to an unrelated question or some overbearing fuckwit with half a million karma will undermine the premise of your question as though you don't know what you are doing? With chatbots you can query a free, compressed representation of StackOverflow, without the terrible attitude.
Idk, I don’t feel that languages need to be/can be ranked. Right now I don’t even believe that much on the right language for the job, but believe in “there was good founding engineer/team, they picked up what they were familiar with and were able to deliver”. People > language. When time will come, another army will rewrite in another language/microservice-size/whatevet
The article is not about ranking the languages per se, but about the drop in activity on stackoverflow likely due to chatGPT and a similar drop in PRs for github.
rWars/lWars were sprileg verboten in earlier versions of The Matrix. Now, with all the resources around to waste (WASTE!), such discord can be used to form (or manipulate) popular opinion and herd competitors towards doom (“and then you paid your people double cuz they did it in Rails”)
If you don’t know what languages to use for your apps without reading a popularity survey, an exciting career awaits you in the field of marketing, customer relations, finance or golf caddy. https://youtu.be/za0nyYbp6is
The same is true for database rankings (db-engines).
If entrants are not artificially inflating "organic" signals via fake content spam (Twitter/X), then the criteria themselves are losing their signal strength (StackOverflow/GitHub).
The diffusion makes it increasingly difficult to understand which channels are important and which correlate to strength in the market.
Unfortunately, these can be more than vanity metrics.
Some VCs or financial markets may use these as methods towards valuation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}