I spent a lot of time in the early 2000s coming up with nasty obfuscation techniques to protect certain IP that inherently needed to be run client-side in casino games. Up to and including inserting bytecode that was custom crafted to intentionally crash off-the-shelf decompilers that had to run the code to disassemble it (and forcing them to phone home in the process where possible!)
My view on obfuscation is that since it's never a valid security practice, it's only admissible for hiding machinery from the general public. For instance, if you have IP you want to protect from average script kiddies. Any serious IP can be replicated by someone with deep pockets anyway. Most other uses of code obfuscation are nefarious, and obfuscated code should always be assumed to be malicious until proven otherwise. I'm not a reputable large company, but no reputable large company should be going to these lengths to hide their process from the user, because doing so serves no valid security purpose.
Agreed - obfuscation is useful for keeping honest people honest. If someone is sufficiently motivated, they will circumvent it, but for the vast majority of people it's just not worth the effort so they'll move to something else.
For example, in our application we have some optionally downloadable content that includes some code for an interpreted language. That code lives on disk in an obfuscated form because we are not yet ready to make the API public (it's on our "someday" roadmap), we don't want to clean up the code for public viewing, and above all because there are different licensing requirements around each content pack.
We looked at various "real" security options and they all have holes, and they all add a ton of complexity. We then also looked at the likely intersection between "people who would pay for this" and "people who could crack this", and there's not much there. In the end, obfuscation is cheap (especially in terms of implementation and maintenance) and steers our real customers away violating the license, and we don't waste resources on dishonest people.
If I'm being charitable, the obfuscation in the article has an out of whack cost/benefit ratio. If I'm being cynical, the obfuscation they are doing strays well into the realm of nefarious. :)
People knock on obfuscation but everything in life is based on trust. Locks being breakable, the fruit stand in front of a shop being unprotected, fences being scalable. Everything is a cost/benefit
It's the curse of ideological purity you see in a lot of the tevh sevtor. Most of these types are of the sort that either something is unbreakable or it's useless.
Just as a fun aside, I was perusing some of my most ancient HN threads and came across this obfuscated monster which I totally forgot about. Pastebin links inside are still active ;)
I don't think OP was defending their own earlier work or otherwise exempting it from their assertion that all obfuscated code should be considered malicious.
> it's only admissible for hiding machinery from the general public.
I had originally read this to imply that somehow it's OK for a casino to hide its machinery from the general public, but it's not OK for TikTok to hide its machinery from the general public, but maybe "machinery" here is intended much more narrowly, and OP thinks it applies neither to casinos nor TikTok.
I read it as the only "legitimate" point is to hide it from the general public. As people with more resources will be able to figure it out. If you view that as legitimate is up to each person to decide. Does the value of trying to hide it from the general public have real value or not. In general the answer might be no.
"General public" was really the wrong term. I meant people with the ability to decompile and use assets or portions of the code for their own games. This was in the early years of Bitcoin when fly-by-night casinos were sprouting up everywhere. Most of them were really badly coded - e.g. the slot machines looked like they'd been drawn by a six year old. Others looked like legitimate casinos, but were actually running cracked versions of white label software. Ours was the only in the space that had a large, professional, fully original codebase... that was what I meant by "machinery", not the machinery governing user interactions with the server (see my response above).
Parent / casino founder here. The casino specialized in original, exotic games. The obfuscated portions of the front-end were game modules (including art assets) that were loaded after login. We had several games that we were filing for patents on. We were also in talks with a much larger online casino about licensing individual games and/or the software as a whole to them. The purpose of the obfuscation was to make it harder for competitors to decompile and get at raw assets or read the math by which the game mechanics worked. For instance, we had a 3D slot machine based on a Rubik's Cube that paid out based on the odds of being able to solve one side in N steps from any given randomly scrambled position. That algorithm had to exist client-side to calculate the odds visible to the user in realtime, along with server-side for confirmation against someone trying to cheat in the client.
I felt it was important to make it as hard as possible for someone to reverse engineer the unique mechanisms. Ultimately, it was probably a waste of time. This is why I think in most cases the uses of obfuscation are at best limited, but they can put a costly stumbling block for competitors if you want to encourage them to license your software rather than copy it. Where I think they tilt toward the nefarious is when they're designed to extract hidden data from end users. As a distinction, what went over the wire between the client game modules and the casino back-end were completely human-readable game states in all cases (besides the user's unique ID and session hash, which were named as such). There were no bullets of obfuscated fingerprints flying around. Any user was free to read what came and went from the API, and even to mess with it by adjusting parameters if they wanted to see what the server would accept or reject.
I think the distinction in what's obfuscated is important. Casino apps are trying to hide their code that detects cheating, number generation, etc, while TikTok is trying to hide its data collection. Obfuscation itself isn't necessarily bad.
Cheating detection was essentially all conducted on the back-end in my casino, but I do think there's a use case for obfuscating some front-end monitoring, e.g. for bot-like inputs. We didn't explicitly ban poker bots, but we didn't make the API guide public, either. The cheating we were most concerned with was poker collusion, which could be detected by combing the log files for certain patterns of play correlated between users or IP addresses.
Random numbers are never generated in the client. Ours were generated on dedicated server separate from anything else - in a different country, for legal reasons - whose sole purpose was to generate random numbers on demand.
You missed the point. maria2 is talking about whitebox crypto. The "whitebox" part means that the decryption process happens on your machine incuding the secrets, which are present in some obfuscated scrambled form in memory. Getting the secret key is a matter of debugging and understanding the obfuscation scheme. A prime example of this is DRM like Widevine (L3) in the chrome browser.
I am really failing to understand the distinction here. Encryption with say, AES has very different properties and use cases compared to an obfuscation scheme. You can use encryption as a part of an obfuscation scheme, but obfuscation is a shell game, all the way down. Crypto is not, mathematically. They are categorically different things, right?
Obfuscation with encryption can be done with good ciphers, like AES, but the key is still shipped with the code, so it's still just cat and mouse.
It's a little different if the key is hardware specific, so each binary only runs on one system and it's hard to extract the keys, but that's not a typical setup. Usually it's this code needs to run on the general public's computers or phones, and that's too general a target to rely on hardware crypto.
Why not? It's just another tool in the security game.
I want to be with you on thinking that all obfuscation is malicious, I know that individuals have every right to obfuscation and privacy as a matter of the 1st and 4th amendments in the US, but I'm not sure I can always say that obfuscation by a corporation is evil, without a more compelling argument. I'm as anti-establishment as they come, too.
I read the GP a bit differently... I didn't read it as saying obfuscation is evil, just that it is ineffective. More like "obfuscation can't prevent reversing, therefore it's not a valid security practice since all it does is slow down the casual observer but does not stop the determined adversary." The statement that most use of obfuscation is nefarious is a corollary... since obfuscation doesn't protect IP it is mostly used to hide malicious activity.
I think l the reason is that it means that they don’t trust or don’t want their users to know what they are doing on your machine. To me, that is already a malicious premise. Even if they aren’t trying to exfiltrate my data or anything.
I guess the acceptable form of obfuscation would mean only IP is protected by it, not everything. I wonder what it would take to enforce this as the norm, certainly doesn't sound easy.
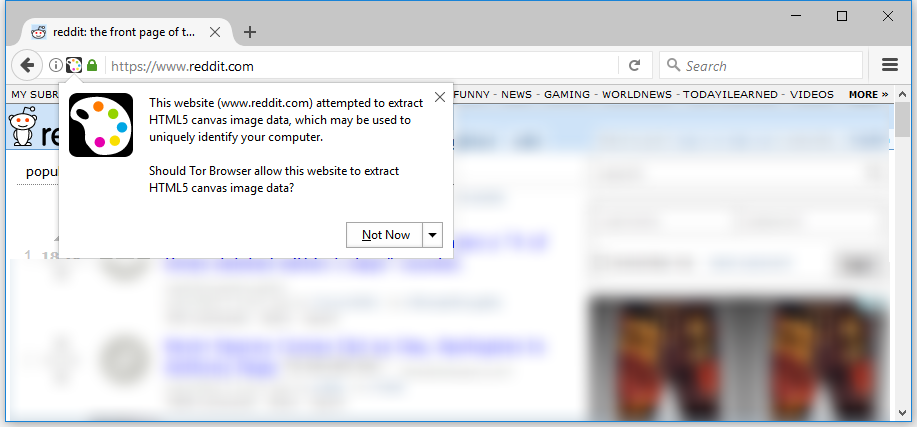
It is interesting, that while technologies like canvas, WebGL or WebRTC were intented for other purposes, their main usage became fingerprinting. For example, WebGL provides valuable information about GPU model and its drivers.
This shows how browser developers race to provide new features ignoring privacy impact.
I don't understand why features that allow fingerprinting (reading back canvas pixels or GPU buffers) are not hidden behind a permission.
It is absurd to claim that the main use of WebRTC is fingerprinting. Especially during the pandemic the world pretty much ran on WebRTC. Real-time media is clearly a pretty core functionality for the web to be a serious application platform, it wasn't just some kind of a trojan horse for tracking.
Now, it is true that a lot of older web APIs do expose too much fingerprinting surface. But the design sensibilities having changed a lot over time, it's just not the case that you can make statements about what browser developers do now based on what designs from a decade or two ago look like. These days privacy is a top issue when it comes to any new browser APIs.
But let's take your question at face value: why aren't thesespecific things behind a permission dialog? Because the permissions would be totally unactionable to a normal user. "This page wants to send you notifications" or "this page wants to use the microphone" is understandable. "This page wants to read pixels from a canvas" isn't. If you go the permission route, the options are to either a) teach users that they need to click through nonsensical permission dialogs, with all the obvious downsides; b) make the notifications so scare or the permissions so inaccessible that the features might as well not exist. And the latter would be bad! Because the legit use cases for e.g. reading from a canvas do exist; they're just pretty rare.
The Privacy Sandbox approach to this is to track and limit how much entropy a site is extracting via these kinds of side channels. So if you legit need to read canvas pixels, you'll have to give up on other features that could leak fingerprinting data. (I personally don't really believe in that approach will work, but it is at least principled. What I'd like to see instead is limiting the use of these APIs to situations where the site has a stable identifier for the user anyway. But that requires getting away from implementing auth with cookies as opaque blobs of data with unknown semantics, and moving to some kind of proper session support where the browsers understands the semantics of signed-in session, and it's made clear to users when they're signing in somewhere and where they're signed in right now. And then you can make a lot better tradeoffs with limiting the fingerprinting surface in the non-signed in cases.)
> "This page wants to send you notifications" or "this page wants to use the microphone" is understandable. "This page wants to read pixels from a canvas" isn't.
That specific wording may be a touch too verbose for the average end user, but it's not impossible nor is it strange. Just include a note about how this is 99% likely a fingerprinting measure; option b) isn't so bad in this case. Of course, due to the nature of how fingerprinting works, the absolute breadth of features that would be gated behind something like this would be offputting.
I am also wary of what you suggested with gating this kind of fingerprinting to when the website has positively identified the user anyway; in a way, this seems to me even more valuable than fingerprint data without an associated "strong" identity.
Giving users the permissions would simply be a training exercise in "I have to say 'yes' or TikTok breaks". Like how Android worked a few years ago with the other permissions.
Android largely works now with these permission prompts, though. TikTok asks you for a million permissions too, and many average end users decline. Many people also opt out of tracking on Facebook et al. when iOS prompts them about it.
The user ‘Joe average’ does not use Tor, does not even know it exists - Tor is used by a completely different segment (of people with ‘above average’ IT skills…)
Of course it's main use is fingerprinting. Do you think WebRTC is instantiated for genuine reasons the majority of the time? That's real absurdity.
WebRTC is instantiated most often by ad networks and anti-fraud services.
Same thing with Chrome's fundamentally insecure AudioContext tracking scheme (yes, it's a tracking scheme), which is used by trackers 99% of the time. It provides audio latency information which is highly unique (why?).
Given Chrome's stated mission of secure APIs and their actions of implementing leaky APIs with zeal, I have reason enough to question their motives.
After all, AudioContext is abused heavily on Google's ad networks. Google knows this.
> It provides audio latency information which is highly unique (why?).
As someone who has worked with WebAudio extensively, and have opened and read many issues in the bug tracker and read many of the proposals... this is just not as nefarious as you are making it seem. I don't disagree that this _can_ be abused by ad tracking networks but I do disagree with the premise that it was somehow an oversight of the spec or implementation which led to this (or even worse, intentional). Providing consistent audio behavior across a wide variety of platforms (Linux, OSX, Windows, Android) along with multiple versions of all those platforms and the myriad hardware in the actual devices is actually just pretty hard. The boring answer here is that to provide low latency audio to support things like games, a lot of decisions have to made about what buffer sizes are appropriate for the underlying hardware and this is what ultimately exposes some information about audio latency on the system. Some of those decisions are limited by the audio APIs of the OS. Some are limited by the capabilities of the hardware. Some are workaround for obscure bugs in either layer. The point is that, as with most software, compromises are made to support an API that people actually need or want to use to make stuff. I also don't think audio latency information is really "highly unique". There are only a handful of buffer sizes which are reasonable based on the desired sample rate and are mostly limited by the OS, meaning at best you can probably identify a persons OS via the AudioContext. Furthermore, I have seen API "improvements" and requests rejected outright due to possibly exposing fingerprinting information. Things that would be really useful to applications which are building audio-centric software won't be implemented because the team takes this issue seriously.
AudioContext latency information can be retrieved without the user's consent or knowledge on websites that never ever use audio. It's a security disaster. I know for a fact that AudioContext is routinely abused on ad networks and by anti-fraud solution providers. Given its widespread use for purposes it wasn't designed for (in fact, this information is used primarily for tracking and spying), it's safe to say it's a tracking scheme.
The fact Google directly and knowingly benefits financially is a smoking gun. They don't give a damn it's not a secure -- in fact they profit on the fact it's a leaky sieve.
You said AudioContext is sometimes used for purposes which benefit the user. Well isn't that swell, the user is maliciously tracked by this security exploit 99% of the time and gets to reap the "benefits" 1% of the time.
Do you mean more websites use webRTC for legitimate purposes than for fingerprinting? Or more instances of it being activated is legitimate or more traffic is legitimate (probs true given bandwidth needed for audio video).
But I suspect by the other two metrics it's correct to say most uses are to fingerprint.
The main reason is that it's really hard to avoid fingerprinting (while providing rich features like WebGL and WebRTC anyway).
A secondary reason is that web browsers started off from a position of leaking fingerprint data all over the place so there's not much incentive to care about it for new features.
(The real conspiracy is that Google added logins to Chrome specifically so that they don't have to rely on fingerprinting. They have a huge incentive to stop fingerprinting because it leaves them as the only entity that can track users.)
I thought the developer of the browser is the only ad provider that _doesn't_ need it (since they have other, better ways to get that intel which their competitors do not).
Also, it's very convenient in a work context if your employer uses G Suite/Workspace. I don't have anything to hide work-wise, and I do everything else in incognito windows.
The fly in the ointment with this theory is why Apple (or even Mozilla) would expose the same kind of information. Apple has only recently started experimenting with ads, and their ads are limited to the apps that they control.
The more benign explanation would be to allow developers to work around device-specific or browser-specific bugs.
(I'm aware Apple changes the GPU Model to "Apple GPU", however they do expose a ton of other properties that make it possible to fingerprint a device.)
Apple devices are in fact fairly difficult to fingerprint. In my experiments [1] all instances of the same hardware model (on iOS, iPadOS, and macOS) give the same fingerprint, so the best a tracker can get is "uses iPhone 14". Better than nothing, but not terribly unique.
They're not that big of a deal, but my two biggest annoyances with RFP:
1. prefers-color-scheme is completely broken, even in the dev tools. Mozilla refuses to fix this in any way, it is allegedly "by design" that you have to disable all RFP protection if you're a web dev and need to test the dark color scheme of your website.
2. Similarly, RFP always vends your timezone as UTC with no way to change.
that's a great way to get even more fingerprinting potential, each additional switch is another bit of identification on top of the actual fingerprint itself.
Continuing the push the browser to be a general app platform is the only way it can survive against native experience, which is already eating into the enthusiasm for the web. It seems like the trend for consumer companies is to maybe launch first on the web for velocity but eventually migrate to native experiences.
I wonder to what degree we can enable hardware performance without leaking user data.
> This shows how browser developers race to provide new features ignoring privacy impact.
I think it showed how many years ago browser vendors were naive with understanding how this tech could be misused.
These days I think browser vendors are very much aware of it and will frequently block features or proposals that they feel compromise on privacy and/or could be used as a tracking vector, especially Firefox and Safari. Sort this list https://mozilla.github.io/standards-positions/ by Mozilla Position to see the reason they reject/refuse to implement standards and proposals.
For those who are unaware of how big of a problem fingerprinting is, there is an EFF website [1]. EU cookie policy is nothing compared to this. There are libraries like fingerprintjs [2] which can generate a pretty stable visitor ID.
If you change or alter some browser APIs in order to make your browser less unique, some payment processors webs may stop working. And webs proxied through CloudFlare will constantly display "Checking if the site connection is secure" page, sometimes in an infinite loop where even solving their captchas won't help.
In most parts of the world, if a person is in a public space, anyone can take a photo of that person, including shop owners. This photo could be considered as a type of "fingerprint" for that person. The only important difference is that in some countries, you are not allowed make money off of such photos.
The Internet is a lot like a big public space, and possibly worse - while you are using certain services (web pages or apps), it might be argued that you are actually "on premises" for that service provider.
The best we can do now is more and more education about what can go wrong with such data collection.
Yes, but taking photos is expensive, fingerprinting online is cheap. Also, there's a difference between taking a photo of the eiffel tower and taking a photo of a bunch of other tourists there (legal), or intentionally targeting and photographing an individual and creating a database of those photos (illegal in most countries).
TikTok changes this algorithm about once every three months. I've reverse-engineered it about two times, and have since given up and decided to run a headless browser to do it for me. I'd love to see some tool developed to automate solving this so I can sign requests in a more limited context (ala Cloudflare Workers / C@E)
Author of the post here, if you have an older version of the script you're able to post or send over I'd love to take a look at it and see what changes they make and potentially automate the extraction.
Yeah, I can get basic user information pretty reliably just from the initial page load.
I had a secondary use case of allowing users to sign-in in order to import the (verified/creator) users they follow, but quickly realized Apple wouldn't allow that data to be used (after the whole OG app ordeal), so I never had a real reason to follow up and crack it again.
I've seen some of these techniques elsewhere; e.g. javascript-obfuscator supports replacing variable names with hex values [1] or transforming call structure into something more complex [2]. Bytecode generation is new to me; is there an existing JS obfuscation tool, preferably open source, that supports it?
I think there are other implementations, but they're proprietary so I didn't look into them very much. There are lots of posts out there about reversing virtualization obfuscation, but not many about implementing it. Seems like most people who put the effort into implementing it tend to prefer selling it commercially (which I suppose makes sense).
It's only for C, but Tigress[1] supports a ton of obfuscation types. Virtualization and JIT are very effective, especially when used together with control flow transforms like Split and Flatten.
Renaming variables or encoding them is fairly trivial to reverse.
Compiling JS to bytecode is not that uncommon, there's a few anti-bot services that rely on it for obfuscation (like recaptcha or f5 shapesecurity) but so far I haven't seen any open source projects for obfuscating this way
FYI, most CAPTCHA and anti-DDoS services (e.g. Cloudflare) do something very similar, sending the user an obfuscated program implemented on top of an obfuscated JS VM, that they effectively have to execute as-is, in a real browser, to get back the correct results the gateway is looking for. This is done to prevent simple scraping scripts (the ScraPy type) from being able to be used to scrape the site. If you want to do scraping, you have to spend the extra overhead of doing it by driving a real browser to do it. (And not even a headless one; they have tricks to detect that, too.)
It also shows how Tiktok may be in violation of several US/EU privacy laws. I really wonder now who this data is shared with. Perhaps someone should bring this article to the FTC’s attention for further review.
Given that the beginning of the "weird string" has a magic number and a version field, I wonder if the point of this is not so much obfuscation as transpilation? The magic number corresponds to ASCII "HNOJ" "@?RC", or perhaps "JONH" "CR?@", which doesn't turn anything up on Google but it seems odd to include that redundant header if your main goal is minification or obfuscation.
It's a custom VM running inside their app, though calling it a VM might be a bit of a stretch because it doesn't appear to be a general purpose computing mechanism but more of higher level command processor.
It sounds like the forthcoming part 2 article will go into more depth.
IIRC not exactly. YouTube provides some arbitrary JavaScript that must be evaluated as a form of a challenge. It changes with every page request, but it’s just a set of math operations. It’s easier to evaluate the JS than to statically analyze it
So the short version is that I would not classify that as a VM, and I don't even believe it's obfuscated. Perhaps there are other extractors that do what you're describing, I didn't go looking
Something hit me when reading this, you know how zknark is touted as tech which in future allow to create app that can work on user private data while preserving user's privacy, could it be used as (opposite) an obfuscation technique to, u encrypt users data inside and zk oracle in user side and send to server. You could reverse engineer what are the inputs to the oracle, but not further what exactly it sends to the server?
zkSNARK allows you to make a proof for a statement that some boolean expression is satisfiable, without leaking any information about how the expression can be satisfied. That helps prove something but not work on any data. The technique you described sounds more like homomorphic encryption, which currently is lots of magnitudes slower than native hardware and lacks practical use.
There needs to be a publicly funded charity that pays people to work fulltime de-obsfucating all the major apps. This should be a well-resourced ongoing operation.
I believe reversing for interoperability purposes is protected (at least here in the US), and I'd guess all reversing is "protected" if one doesn't share the resulting code (as with TFA), but I would bet that a crowdsourced setup like you're describing would run afoul of patent and copyright laws and ultimately the legal system is "he who has the most lawyers wins"
I have often wondered what the legal area is for sharing a Ghidra database that merely labels existing code, but I haven't looked into how much of the original binary gets packaged up with such a database
That HTTP request is kind of hideous. All those extra parameters that have nothing to do with what the response will end up being, and which change often. Seems like a great way to toss out all your API-response edge-cache-ability.
With HTTPS you need to own the edge cache yourself and most will have options to ignore the headers and URL parameters that you want. That way they can log the tracking data and serve the cached data as if they were never there.
This is mostly true — though keep in mind that corporate forward-proxy caches still work under strict TLS, by installing root CA certs through GPOs on corporate machines, that re-sign all connections.
More importantly, if you're talking to a browser, the browser's own cache is in play. It's not an edge cache, per se, but it's just as important as one, and acts very similar to one.
Can I conclude that TikTok implemented a custom VM in Javascript ?
Any idea what its used for and how many instructions it can process and are there other comparable implementations ?
Someone reported that he just had a typo in the twitter handle, IIRC an extra "r" at the end; FWIW, navigating up one level also has a link to the twitter handle and works just fine: https://twitter.com/nullpt_rs
Wouldn't an example be a job that requires it? Are you attempting a meta comment, and really mean something like "anyone can quit a job that requires social media usage"?
Your statement does not take into account related factors, e.g. you have a job you like and need, but the job changed to require social media use; you love and help a remote family member who prefers using social media to stay in touch, etc.
In some similar statements, e.g. "If you don't want to be in car accidents, then don't be in them" the logical flaw is clear: Prevention involves a number of steps and assessments, skill, and some luck. Changing it to say "If you are concerned about car accidents, stay out of cars" would be equally problematic.
> void 0 (a fancy obfuscated way of saying undefined)
Kind of. But it was possible at one point, maybe still is, to rebind `undefined` to some other value, causing trouble. `void` is an operator, a language keyword; it’s guaranteed to give you the true undefined value. (In other words, the value whose type is `undefined`.)
If you’re coding against an environment as adversarial as these people clearly believe they are, you’d go with `void` as well.
Another reason to use `void 0` is that "void 0" takes only 6 characters while "undefined" takes 9, saving some bandwidth. It is common practice for JavaScript minifiers to use this substitution.
It’s really more that there is no reason not to do it. Void is marginally safer as well as shorter, so any minifier/transpile step etc will make this substitution.
It doesn’t. It just requires them to follow the law, like other countries do. The problem comes from the fact that American companies are used to buying their way around the laws, and in this case they can’t.
{kind=link}
I spent a lot of time in the early 2000s coming up with nasty obfuscation techniques to protect certain IP that inherently needed to be run client-side in casino games. Up to and including inserting bytecode that was custom crafted to intentionally crash off-the-shelf decompilers that had to run the code to disassemble it (and forcing them to phone home in the process where possible!)
My view on obfuscation is that since it's never a valid security practice, it's only admissible for hiding machinery from the general public. For instance, if you have IP you want to protect from average script kiddies. Any serious IP can be replicated by someone with deep pockets anyway. Most other uses of code obfuscation are nefarious, and obfuscated code should always be assumed to be malicious until proven otherwise. I'm not a reputable large company, but no reputable large company should be going to these lengths to hide their process from the user, because doing so serves no valid security purpose.