> Meanwhile vast amounts of memory and CPU power mean flyweights and object pools aren't so useful
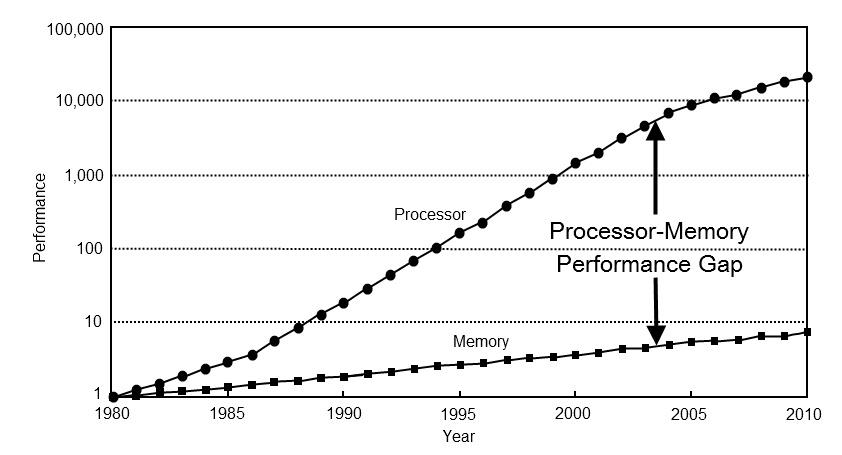
I'd argue that they still are relevant. The only thing that's seen more impressive growth than memory volume is the relative cost of a cache miss. So the great irony is, one of the most efficient ways to sabotage your CPU power is to make use of all that RAM.
> The only thing that's seen more impressive growth than memory volume is the relative cost of a cache miss.
Has the cost of cache misses truly increased? (Also: relative to what?)
Today's CPUs have far larger caches than in the past (and not to mention a lot faster too), so the number of cache misses and the time cost of each cache miss for the same program on a modern CPU should be much lower—right?
It depends a lot on how you frame it. The absolute time spent waiting on memory has improved, although not at nearly the rate of other things[1]. When I was young and rosy cheeked, the performance gap was only order of magnitude, but it now spans more than three. So the cost of a cache miss, in terms of number of CPU cycles lost (which is what I meant by the term "relative") has grown by quite a bit. Worse, while we keep adding CPU cores, there's still only the one memory bus. Even if one core is waiting on a memory access, the others can keep working - but only for as long as they don't need to access memory, either. Which may not be for very long if, for example, you're allocating lots of short-lived objects, or using persistent data structures. In memory intensive applications, things can quickly back up so that all the cores are blocked up, waiting in line behind each other for data. If you look at the cost of this in terms of per-core CPU time rather than wall clock time, things start to look pretty icky. And this can be a devious thing, because it's an effect that isn't typically shown in the output of a performance profiler.
On the cache side, it's true that caches are bigger. But then we run into that old saw about software people's greatest achievement being to negate to efforts of hardware people. Caches get twice as big, and programmers decide the best thing to do with all that extra space is using 64-bit numbers as a matter of habit, or perhaps even switching to programming languages that don't have 32-bit numbers. Or by switching to dynamic languages that cram the cache full of pointers and object headers. Things like that.
Which isn't to say that all of these practices are objectively bad - spending computing resources on human productivity is typically a very good trade-off. Just that there's no such thing as a free lunch. Memory usage still has a performance cost, and, in stark contrast to how things worked a quarter century ago, it now kicks in long before the system starts experiencing actual memory pressure.
Nowadays there are increasingly many memory buses. I think the top-end Epyc uses 8 of them, that may each simultaneously have an operation in flight, each with its own queue. Lesser Zen2s have four memory buses.
Perhaps I over-simplified, but, from what I've seen, performance benefits from multi-channel memory architectures are pretty variable and not something a programmer should typically assume.
Partially this is due to configuration variability. A lot of laptops are still configured in single channel mode. Even high-end laptops tend to be dual channel setups, even if the CPU itself supports more. I'm inclined to say that high-end CPUs configured for 4 (or more) channels are rare enough that you probably shouldn't expect to be able to enjoy one unless you're developing in-house software where you can know exactly what kind of hardware you'll be running on.
And partially it's due to contention. All the memory channels in the world won't help you when memory access starts to pile up on the same bank. Which is, in practice, going to be something that will happen all the time if you're not taking steps to keep it form happening, because that's the kind of unhelpful jerk that stochastic processes are.
Agreed. I did not mean to detract from your point, and awareness of bus architecture is so limited that vendors usually get away with cheaping out on memory channels so we often have even fewer than our CPU module could exercise.
In practice if you have more memory buses they are more likely to be useful to help more processes or threads make simultaneous progress than to speed up one process. For a single thread to make good use of more memory buses usually requires using memory pre-fetch intrinsics and memory sequestration, and even then it is hard to keep more than two or three usefully engaged for that thread.
I think the parent talks about the relation between miss/hit, not the actual cost of a miss. In other words, if a piece of code took 100ms with 100% cache hit and 200ms with 0% hit but now it takes 20ms with 100% hit and 100ms with 0% hit, your code is 5 times slower with cache misses, when before it was only 2 times slower. Yeah, it's faster than before, but the relative cost in terms of your available performance has increased.
And I'd agree with that statement. I have been doing some heavy profiling lately and it's fun to see how good are modern processors at executing even non-optimal code if it's cache friendly. However, the moment it needs to hit L3 cache or further, the pipeline stalls and performance goes down the drain.
{kind=link}
I'd argue that they still are relevant. The only thing that's seen more impressive growth than memory volume is the relative cost of a cache miss. So the great irony is, one of the most efficient ways to sabotage your CPU power is to make use of all that RAM.