Sure, humans make mistakes... but rarely, vanishingly rarely about commands they use often. Are you going to make a non-typo kind of mistake when typing `ls -l`? AI hallucinations don't happen all the time, but they happen so much more often than "vanishingly rarely".
That's why you can't just vibe-code something and expect it to work 100% correctly with no design flaws, you need to check the AI's output and correct its mistakes. Just yesterday I corrected a Claude-generated PR that my colleague had started, but hadn't had time to finish checking before he went on vacation. He'd caught most of its mistakes, but there was one unit test that showed that Claude had completely misunderstood how a couple of our services are intended to work together. The kind of mistake a human would never have made: a novice wouldn't have understood those services enough to use them in the first place, and an expert would have understood them and how they are supposed to work together.
You always, always, have to double-check the output of LLMs. Their error rate is quite low, thankfully, but on work of any significant size their error rate is pretty much never zero. So if you don't double-check them then you're likely to end up introducing more bugs than you're fixing in any given week, leading to a codebase whose quality is slowly getting worse.
Every day users? Probably not many. It forcibly disables lots of nice-to-have features.
But users who need a highly secure phone? It’s entirely possible to use the phone without media embeds in iMessage, or shared photo albums, or websites loading in 900 fonts. It’s a trade off likely worth making in some situations.
You can make a shared photo album with family members. It’s everyone else that is problematic with the feature enabled. In my case I only want to share with my wife and son so it wasn’t a detractor for me.
I’ve used it on my personal iPhone since the feature was released. The impact to my life has been minor. I can’t share some thing with my wife in the health app and my son can’t SharePlay with me in the car while I use CarPlay.
I use Preact without reactivity. That way we can have familiar components that look like React (including strong typing, Typescript / TSX), server-side rendering and still have explicit render calls using an MVC pattern.
View triggers an event -> Controller receives event, updating the model as it sees fit -> Controller calls render to update views
Model knows nothing about controller or views, so they're independently testable. Models and views are composed of a tree of entities (model) and components (views). Controller is the glue. Also, API calls are done by the controller.
So it is more of an Entity-Boundary-Control pattern.
From what I can tell, they do full page reloads when visiting a different page, and use Preact for building UIs using components. Those components and pages then get rendered on the server as typical template engines.
Our approach is actually very cost-effective compared to alternatives. Our browser uses a token-efficient LLM-friendly representation of the webpage that keeps context size low, while also allowing small and efficient models to handle the low-level navigation. This means agents like Claude can work at a higher abstraction level rather than burning tokens on every click and scroll, which would be far more expensive
are your evals / comparisons publicly/3rd party reproducible?
If it's "trust me, I did a fair comparison", that's not going to fly today. There's too much lying in society, trusting people trying to sell you something to be telling the truth is not the default anymore, skepticism is
I'm paying a fixed amount on Claude and other agents, so "more tokens" is "free" for me. There's a lot of niche tools out there but I think we all have "subscription fatigue".
But maybe that's just me - Maybe im just not your target audience :)
That doesn't work very well if your developers are on Windows (and most are). Uneven Git support for symbolic links across platforms is going to end up causing more problems than it solves.
It's why I wrapped my tiny skills repo with a script that softlink them into whichever is your skills folder, defaulting to Claude, but could be any other.
I treat my skills the same as I would write tiny bash scripts and fish functions in the days gone to simplify my life by writing 2 words instead of 2 sentences. Tiny improvement that only makes sense for a programmer at heart.
They probably organize individual accounts the same as organization accounts for larger groups of users at the same company internally since it all rolls up to one billing. That's my first pass guess at least.
I think it's more likely that their account was disabled for other reasons, but they blamed the last thing they were doing before the account was closed.
It reads like he had a circular prompt process running, where multiple instances of Claude were solving problems, feeding results to each other, and possibly updating each other's control files?
They were trying to optimize a CLAUDE.md file which belonged to a project template. The outer Claude instance iterated on the file. To test the result, the human in the loop instantiated a new project from the template, launched an inner Claude instance along with the new project, assessed whether inner Claude worked as expected with the CLAUDE.md in the freshly generated project. They then gave the feedback back to outer Claude.
So, no circular prompt feeding at all. Just a normal iterate-test-repeat loop that happened to involve two agents.
I think the idea is fine, but what might end up happening is that one agent gets unhinged and "asks" another agent to do more and more crazy stuff, and they get in a loop where everything gets flagged. Remember that "bots configured to add a book at +0.01$ on amazon, reached 1M$ for the book" a while ago. Kinda like that, but with prompts.
Could anyone explain to me what the problem is with this? I thought I was fairly up to date on these things, but this was a surprise to me. I see the sibling comment getting downvoted but I promise I'm asking this in good faith, even if it might seem like a silly question (?) for some reason.
From what I'm reading in other comments, the problem was Claude1 got increasingly "frustrated" with Claude2's inability to do whatever the human was asking, and started breaking it's own rules (using ALL CAPS).
Sort of like MS's old chatbot that turned into a Nazi overnight, but this time with one agent simply getting tired of the other agent's lack of progress (for some definition of progress - I'm still not entirely sure what the author was feeding into Claude1 alongside errors from Claude2).
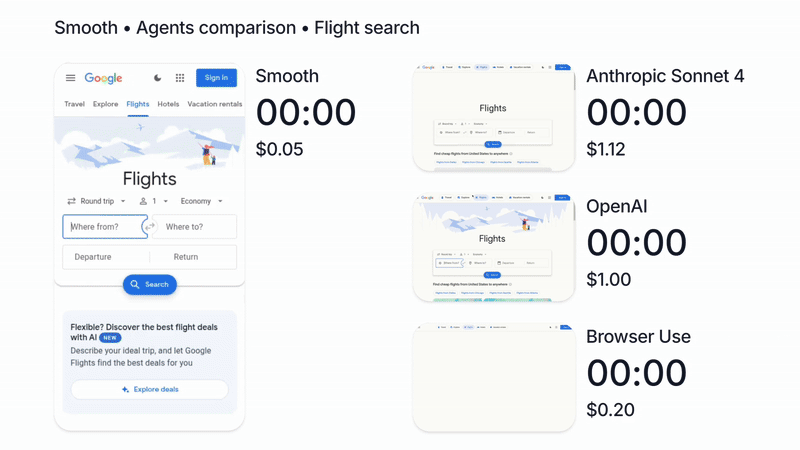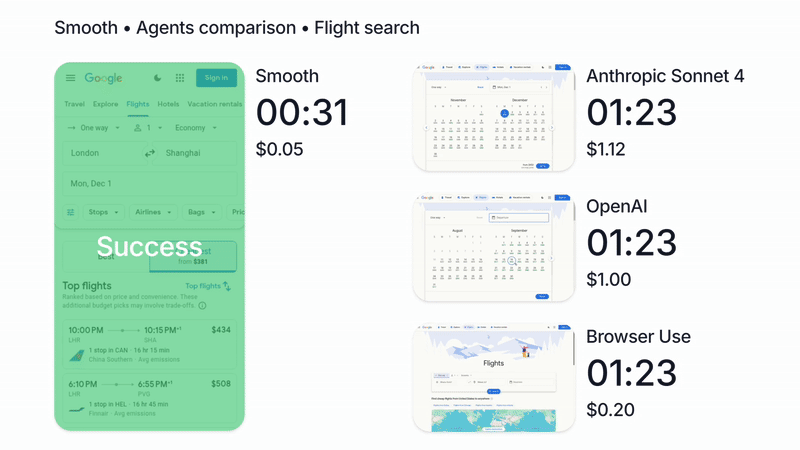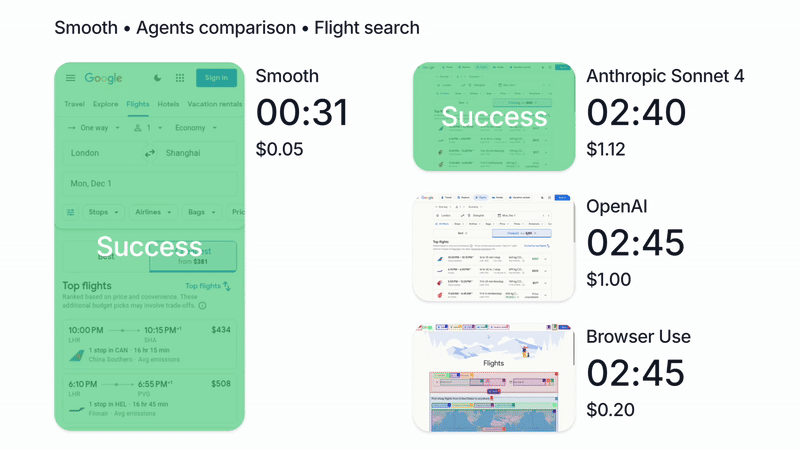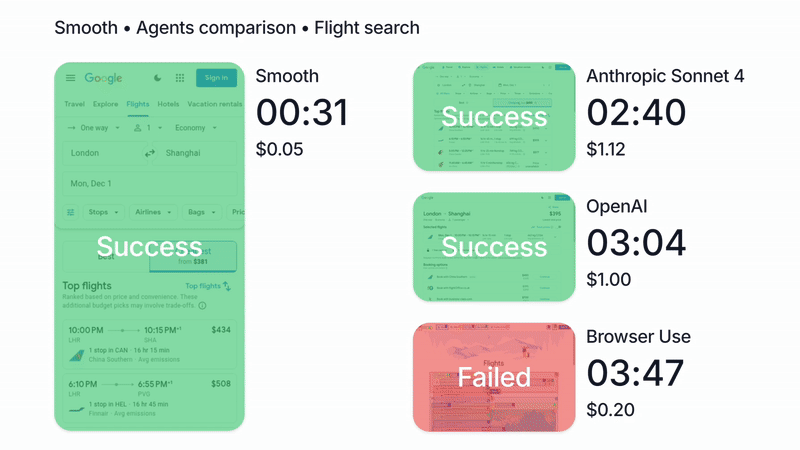{kind=link}
reply