Very nice work. Training these from scratch is a big undertaking.
- Did you train the encoder & decoder together or separately? It would be nice to have the encoder representation be compatible with the existing whisper implementation since it would mean you could swap your implementation into models where its used as a component, like in the recent Voxtral model. I'd imagine it also might make training a bit faster as well.
- Did you consider training the turbo model as well?
EPA range tends to be pessimistic for EVs as it assumes you are always traveling at highway speeds. Even small reductions in speeds can make EVs much more efficient since drag is quadratic. A quick google search shows Prius prime owners reporting 4-5.5 miles/kwh, so the 3-6 mile range is entirely plausible.
> EPA range tends to be pessimistic for EVs as it assumes you are always traveling at highway speeds.
EV EPA range historically has been overstated. However, the water is muddied because the EPA doesn't really force the manufacturers to give an accurate number. A manufacturer can choose a highway only test, but then also arbitrarily decide to derate the value (EPA example is 70%). A manufacturer can choose to include city driving in the rating and weigh it accordingly and also derate the value (if they want).
Tesla traditionally (still the vast majority of new and used EV market share) has been the only manufacturer that uses the highway + city driving tests. People then get surprised when the car cannot do the full range at 85 MPH.
All in all, this is the EPAs fault. For EVs they really need two numbers, city driving range and highway driving range. EVs are so much more efficient than ICE that speed makes a huge difference given there substantially smaller energy density.
You can buy stock in a solar "yieldco", which is exactly this. It holds the assets of solar farms and pays out the cashflows. There were a lot circa 2018, I believe Brookfield bought up a bunch, so there may be fewer options now.
If you are hosting whisper yourself, you can do something slightly more elegant, but with the same effect. You can downsample/pool the context 2:1 (or potentially more) a few layers into the encoder. That allows you to do the equivalent of speeding up audio without worry about potential spectral losses. For whisper large v3, that gets you nearly double throughput in exchange for a relative ~4% WER increase.
Do you have more details or examples on how to downsample the context in the encoder? I treat the encoder as an opaque block, so I have no idea where to start.
It's a very simple change in a vanilla python implementation. The encoder is a set of attention blocks, and the length of the attention can be changed without changing the calculation at all.
Here(https://github.com/openai/whisper/blob/main/whisper/model.py...) is the relevant code in the whisper repo. You'd just need to change the for loop to an enumerate and subsample the context along its length at the point you want. I believe it would be:
for i, block in enumerate(self.blocks):
x = block(x)
if i==4:
x = x[,,::2]
Most of this decline isn't driven by a change in current fertility rates, but instead by a persistent trend downward in number of reproductive-aged adults. That was locked in by the fertility rates 20-40 years ago. These things move in the timescale of decades. Even if policy were reasonably successful, it would be a quarter of a century before things stabilized.
The difference in throughput for local versus distributed orchestration would mainly come from serdes, networking, switching. Serdes can be substantial. Networking and switching has been aggressively offloaded from CPU through better hardware support.
Individual tasks would definitely have better latency, but I'd suspect the impact on throughput/CPU usage might be muted. Of course at the extremes (very small jobs, very large/complex objects being passed) you'd see big gains.
By way of a single example, we've been migrating recently from spark to duckdb. Our jobs are not huge, but too big for a single 'normal' machine. We've gone from a 2.5 hour runtime on a cluster of 10 machines (40,vCPU total) to a 15 minute runtime on a 32vCPU single machine. I don't know for sure, but I think this is largely because it eliminates expensive shuffles and serde. Obviously results vary hugely depending on workload, and some jobs are simply too big even for a 192 core machine. But I suspect a high proportion of workloads would be better run on single large machines nowadays
A cluster of 10 machines with 40 vCPUs in total would equate to 4 vCPUs per machine. I am not familiar with Spark internals but in the realm of distributed databases such a setup would generally make no sense at all (to me). So I think you're correct that most of the overhead was caused by machine-to-machine byte juggling. 4 vCPUs is nothing.
I suspect you would be able to cut down the 2.5hr runtime dramatically even with the Spark if you just deployed it as a single instance on that very same 32vCPU machine.
Your measuring wall time, not CPU time. It may be that they are similar, but I'd suspect you aren't loading the worker nodes well. If the savings are from the reduced shuffles & serde, it's probably something you can measure. I'd be curious to see the findings.
I'm not against using simple methods where appropriate. 95% of the companies out there probably do not need frameworks like spark. I think the main argument against them is operational complexity though, not the compute overhead.
When you talk between remote machines, you have to translate to a format that can transmitted and distributed between machines(serialization). You then have to undo at the other end(deserialization). If what you are sending along is just a few floats, that can be very cheap. If you're sending along a large nested dictionary or even a full program, not so much.
Imagine an example where you have two arrays of 1 billion numbers, and you want to add them pairwise. You could use spark to do that by having each "task" be a single addition. But the time it would take to structure and transmit the 1 billion requests will be many multiples of the amount of time it would take to just do the additions.
Longshoreman is not a typical blue collar job. You cannot just go out and become one today. It is a nepotistic profession where positions are passed within families and closely guarded from external competition. Go read The Box. It outlines all of this in the later chapters.
It seems like the program has some issues to iron out, but the general concept is really compelling. Being able to group both the supply and demand side of delivery systems could make it really efficient. When you increase driver productivity like that it should leave room to increase their wages, so hopefully that happens here.
It would be great to see programs like this in the US. The closest I can think of is MealPal, where they simplify logistics by having each restaurant only focus on 1-2 dishes so they can churn them out incredibly quickly. I know Marc Lore's Wonder is also trying something similar with ghost kitchens, but don't know much of the details. Being able to serve more people with the same store space also cuts down on the fixed costs/person. I enjoy cooking, but it is hugely inefficient for everyone to do it for themselves at a civilizational level. If we could make healthy restaurants cost competitive with home cooking, it would probably equate to trillions in saved time.
Norway's vehicle fleet is now 25% EVs and their per capita electricity usage is the same it was a decade ago[1]. Oil infrastructure uses a ton of electricity, and California refines most of the oil it consumes because of its geography and unique fuel blend. EVs may actually reduce California's overall electricity usage.
This feels like a convenient excuse for cost cutting. Experienced people are expensive. If you need to make cuts, it's an easy place to start.
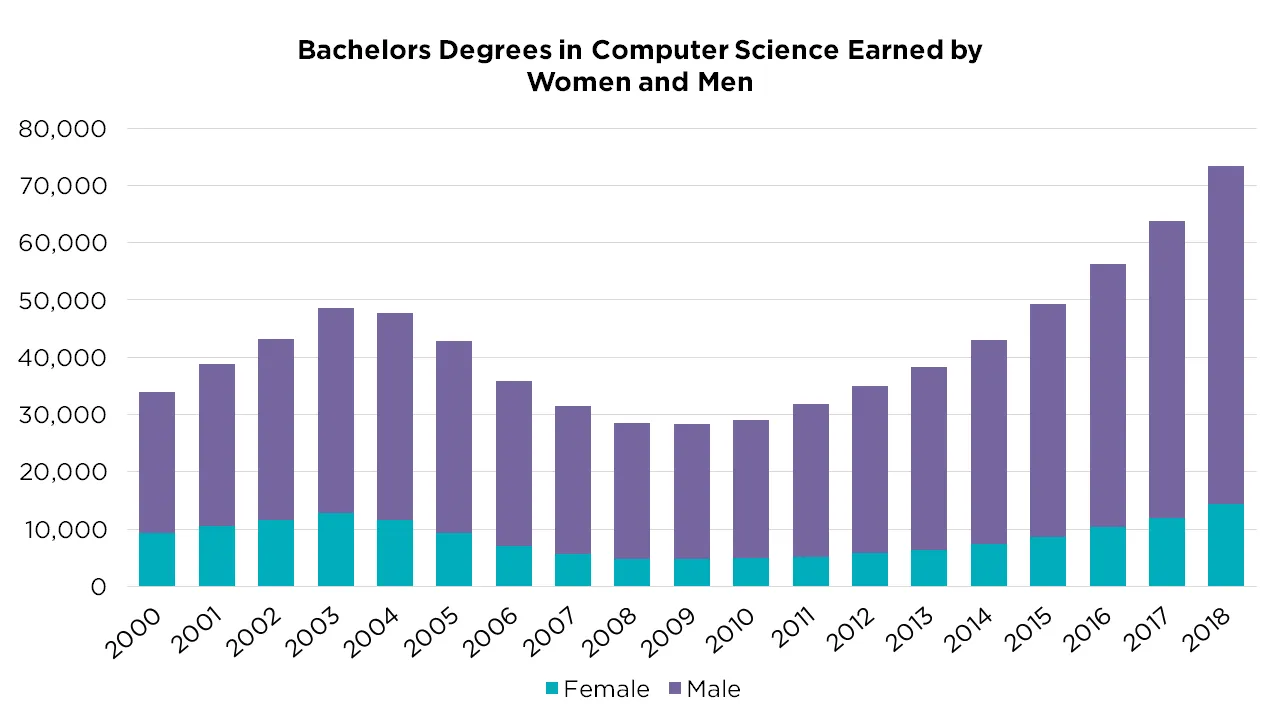
Ironically, it's felt like US tech companies have been moving in the opposite direction lately. There seems to be a lot of demand for very senior engineers at the same time it's become increasingly difficult for new grads to find jobs. Maybe this is just a function of the pinch in CS graduation rates ~15 years ago[1]. From my experience as a manager, the premium you pay for senior talent also seems like a good deal. Even among good programs, there is huge variance in the productivity of new grads and training is a difficult proposition when changing jobs every 2 years is common.
{kind=link}
- Did you train the encoder & decoder together or separately? It would be nice to have the encoder representation be compatible with the existing whisper implementation since it would mean you could swap your implementation into models where its used as a component, like in the recent Voxtral model. I'd imagine it also might make training a bit faster as well.
- Did you consider training the turbo model as well?
reply