The difference is that SAT/SMT solvers have primarily relied on single-threaded algorithmic improvements [1] and unlike neural networks, we have not [yet] discovered a uniformly effective strategy for leveraging additional computation to accelerate wall-clock runtime. [2]
RETE family algorithms did turn out to be somewhat parallelizable, enough to get a real speed-up on ordinary multicore CPUs. There was an idea in the 1980s that symbolic AI would be massively parallelizable that turned out to be a disappointment.
You could argue that since automatic differentiation and symbolic differentiation are equivalent, [1] symbolic AI did succeed by becoming massively parallelizable, we just needed to scale up the data and hardware in kind.
In the comments, zero_k posted a link to the SAT competition's parallel track. The 2025 results page is here: https://satcompetition.github.io/2025/results.html Parallel solvers consistently score lower (take less time) than single-threaded solvers, and solve more instances within the time limit. Probably the speedup is nowhere near proportional to the amount of parallelism, but if you just want to get results a little bit faster, throwing more cores at the problem does seem like it generally works.
> The solvers participating in this track will be executed with a wall-clock time limit of 1000 seconds. Each solver will be run an a single AWS machine of the type m6i.16xlarge, which has 64 virtual cores and 256GB of memory.
For comparison, an H100 has 14,592 CUDA cores, with GPU clusters measured in the exaflops. The scaling exponents are clearly favorable for LLM training and inference, but whether the same algorithms used for parallel SAT would benefit from compute scaling is unclear. I maintain that either (1) SAT researchers have not yet learned the bitter lesson, or (2) it is not applicable across all of AI as Sutton claims.
Gingsberg stole it from Yeats — “the best lack all conviction…” / “the best minds of my generation…” — many similar verses, e.g., “what rough beast…” / “what sphinx of cement…”
Those aren't nearly close enough to be considered stolen. Possibly allusions (which is not stealing), but even then, the only similarity of the bests is "The best" usage. Nothing about the rest of the lines, or before, are similar enough to be "stolen" (potentially the Ginsberg troping Yeat's "full of passionate intensity" of the worst into his best's "madness, starving hysterical", but that too is allusion, not stealing).
The best lack all conviction, while the worst //
Are full of passionate intensity.
vs
I saw the best minds of my generation destroyed by madness, starving hysterical naked, //
dragging themselves through the negro streets at dawn looking for an angry fix,
Depending on how comfortable you are with model theory you might also enjoy Dzhafarov and Mummert’s textbook, which first brought the subject to my attention.
This is roughly the intuition I have developed -- any computational function requires time and space to evaluate. Most computations carry with them some epistemic or aleatoric modeling uncertainty, but sometimes even a perfectly deterministic function with a worst case constant time complexity is worth approximating, as the constant factor may be prohibitive.
Given an exact decision procedure with astronomical lower bounds, and an approximate one that is identical on 99.99% of IID sampled inputs that takes a second to evaluate, which would you prefer? Given a low latency, high variance approximation, would you be willing to exchange latency for lower variance? Engineering is all about such tradeoffs.
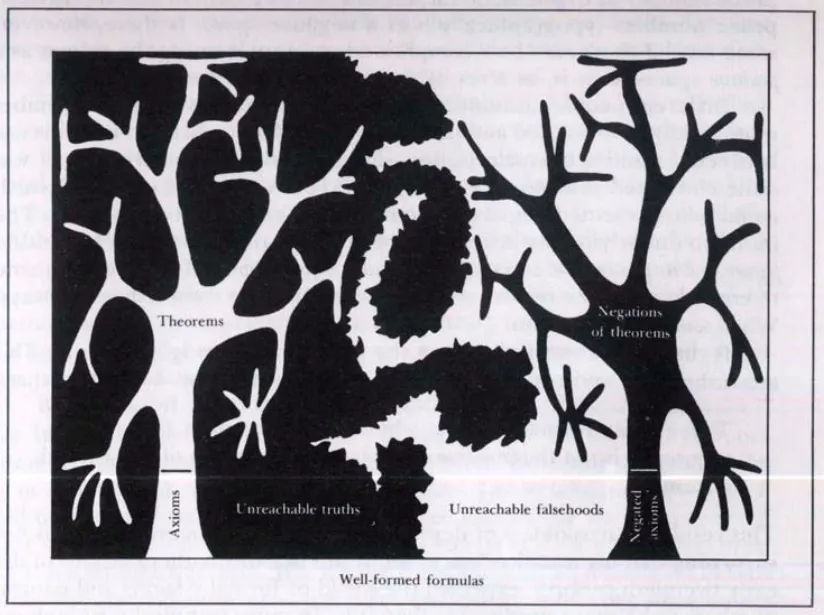
There is a neat picture [1] in GEB that captures a similar idea.
FWIW, I’ve had a very similar encounter with another famous AI influencer who started lecturing me on fake automata theory that any CS undergrad would have picked up on. 140k+ followers, featured on the all the big podcasts (Lex, MLST). I never corrected him but made a mental note not to trust the guy.
This is a handy tool, but I wish it supported edge snapping. If you inspect the generated LaTeX it doesn't actually link up the FSM states, it just anchors them to raw TikZ coordinates.
{kind=link}
[1]: https://arxiv.org/pdf/2008.02215
[2]: https://news.ycombinator.com/item?id=36081350