At Scale (scale.com), we strongly believe that the “open-source” alternative to this is pretty critical.
We’ve built this index for autonomous driving datasets (https://scale.com/open-datasets) and are building that out for other domains right now.
Open source data has been a pillar to progress in ML (starting with ImageNet). It should continue to be the case that data that enables researches is sufficiently democratized.
One thing I’ll mention is that this is true both at the very early stages of a ML project, and even when an ML project is scaled up and in production. Oftentimes, the data pipeline is the true way in which a model will improve versus anything else, so it’s pretty critical that these data pipelines are setup to get an initial dataset but also to scale properly.
It’s one reason I started Scale (scale.com). It was viscerally clear that the real bottleneck to ML was getting the needed data, and in our case, annotating that data appropriately. It is very heartening to hear it echoed in this whole thread that data is very clearly what “matters” for ML.
founder of Scale (scale.com) here! We worked with OpenAI to produce the human preferences to power this research, and are generally very excited about it :)
Any thoughts about offering this as as service? There are lots of hobbyists who have been playing around with GPT-2 text generation, and it'd be sweet if you could just fire up a simple form URL with two text snippets, two options, and it trains on feedback.
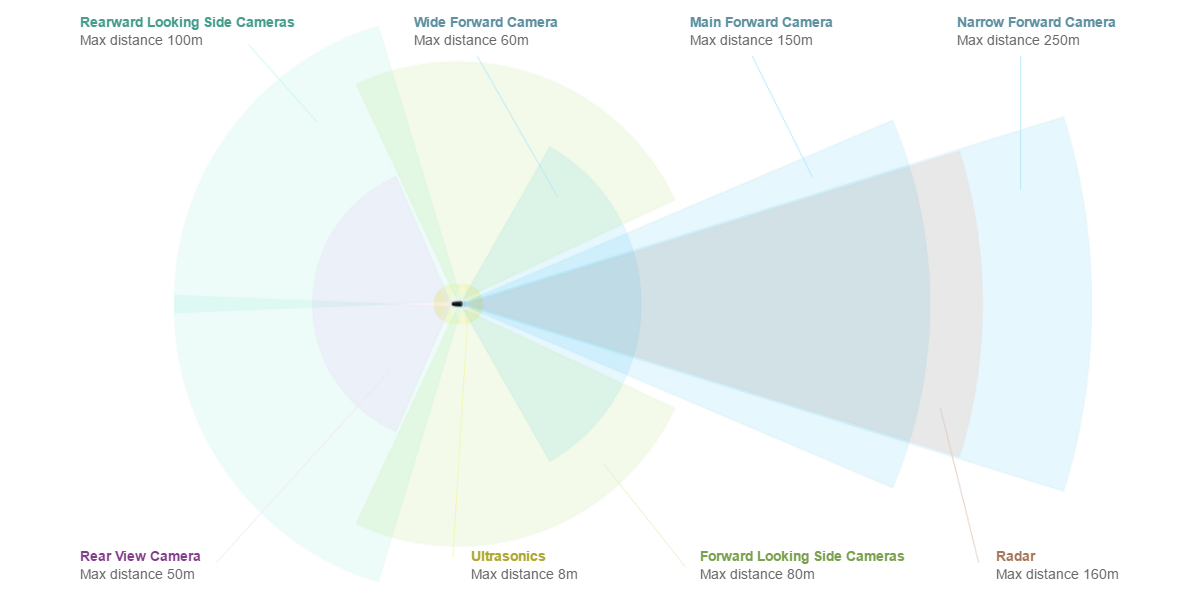
2. Stereo depth estimation is quite unreliable in practice because it requires you to match up pixels between the two images very precisely (1-2px difference can be a large disparity in distance), so it is not reliably used.
We have many clients who have switched from Hive. There’s usually a step change improvement in quality and scalability—up to 10x improvement in error rates.
Very similar to the Magic Wand tool in Photoshop which gives a good starting point and can be improved on manually in the problem areas where colors are ambiguous.
hey @ayw. your story is really inspiring! I am currently studying full stack web development via online courses as I have few startup ideas that I want to work on that I believe to be promising. Is there any Machine learning course you specifically recommend taking in order to come up to speed with the AI technology and also if you could share some tips on becoming a first time founder especially getting the funding from a silicon valley VC as in what do they really look for when investing in a startup started by someone with no prior startup experience then that would be really great! Thanks ahead of time!
We do use AI and ML to help making the labeling process more efficient, but you are correct we do have scaled human insight that ensures very high quality.
One difference from "Not Hotdog" is that our data is used to power the algorithms of other AI/ML companies like OpenAI, Waymo, Lyft, etc., so it's imperative that we have impeccable quality. That necessitates humans to ensure accuracy, particularly in safety-critical applications like self-driving cars.
I just wanted to chime in that we're a YC company as well (S16), and I'm thankful to the HN community for having been supportive through our whole journey.
It's a great idea, but I can't believe that the market is that large for this kind of data for 2 reasons: 1 - there's certainly a point of diminishing returns; and 2 - having good, clean data that's proprietary is a _huge_ differentiator. If I am the leader in autonomous driving, I doubt I'd want to pay someone else to help them train models that will help my competitors.
The problem I see with wading into other subfields (like my own) that need high quality training datasets, is that the datasets may be proprietary, and may not really overlap that much between companies in the same industry. For example, assembly line datasets for companies making almost the same product may be vastly different. I'm really struggling to see how you can possibly achieve the same scale in other industries.
Is it weird sharing the same name as a fashion icon ;)
And I'm curious about your ML "stack". Particularly the chicken and egg problem. Are you using something like Tensorflow with pre-trained binaries, perhaps from a vendor? Or is it 100% proprietary. Thanks!
Re 1—It has been a bit of annoyance growing up (for example, Google autocorrects "Alexandr Wang" to "Alexander Wang"), but we run different circles ;)
Re 2—As with most companies working on ML these days, our stack is not fully proprietary. We don't take too strong an opinion on ML framework and use both Tensorflow and Pytorch currently. We generally use neural network architectures from the literature and then iterate on top of them to suit our unique problem requirements.
The biggest change is your jobs goes from doing things (which makes sense) to building an incredible team that can do things (which is a more unintuitive job). In the limit, it’s always a people business.
Overcome many challenges, but per my last answer, building a team of the best people has been the most important and most challenging. That, and learning how to do sales ;)
Too many mentors. People in Silicon Valley are incredibly helpful. To name a few: Dan Levine, Mike Volpi, Nat Friedman, Adam D’Angelo, Ilya Sukhar, Jonathan Swanson, Albert Ni, Jeff Arnold, Charlie Cheever, and Drew Houston to name a few. I’m very very lucky.
We have a rule when hiring people—we look for people with an internal locus of control. Roughly speaking, this means people who believe they have control over outcomes in their life, as opposed to external forces beyond their control.
It’s a small thing, but it’s surprising easy to spot once you look for it. And it really matters—startups are the business of building something from nothing. You need people who believe they can bend the earth.
Congratulations on your fast growth! It is always great to see examples of companies like yours actually solving real-world problems in AI with original ideas and obtaining large clients that rely on your work.
I'm really looking forward to more of what Scale will do in the future!
Self-driving is one of many applications of AI/ML to the real world, each of which likely requires high-quality labeled data to truly be production-ready. This includes other robotics, self-checkout like Amazon Go, natural language understanding, and more.
Second, self-driving as a problem space will need labels for a very long time. In an application where (1) verifiable model performance is paramount, and (2) the models need to be extremely robust for cars to be safe, the need for labeled data is only magnified.
I see, I saw that you guys were doing a huge amount of value-add with things like segmentation for self-driving but didn't know you were differentiating yourselves from other competitors in the general labelling space like e.g. Mechanical Turk. Cheers!
This comment does not represent the company's viewpoint, and cardigan is not speaking on behalf of Scale.
We are very excited to have been able to work with Lyft in open-sourcing this dataset and advancing the research community. We are also very grateful to Lyft for choosing to leverage our point cloud viewer and have credited the annotations to us on their launch page.
Hopefully not. Cardigan obviously is has the company's interest in mind, even if perhaps the execution is a little flawed. Cardigan has just learnt a lot about PR and also gave a lot of free airtime to Scale.
Also hopefully Scale will use this opportunity to educate team members about situations like this.
That’s a strange take on this. Not all staff are authorized to speak on the company’s behalf. That’s true almost anywhere I’ve worked. Your efforts cannot always be recognized externally. NDAs and various other types of contracts commonly outline that.
I would be surprised if many people here really just assumed that a pseudonymous user chatting with us in the HN comments was speaking on behalf of the company in an official capacity. I mean, obviously there are legal niceties to be observed and he should have appended the usual disclaimers, blah blah blah, but we do have common sense here right?
No, people don't have common sense. People should not post publicly on behalf of their employer without running it by a manager. This is lesson one at every major corporate introduction and I now understand why, because people don't have common sense.
I didn't say anything about whether he should or should not have spoken out about the deal. And I specifically said that common sense doesn't cut the mustard legally. But I am asserting that the damage from people supposedly assuming that he was speaking officially is speculative and likely zero.
This isn’t really about employee recognition. The whole comment was about attribution for the company and marketing the partnership with Scale. Which is pretty standard in some business arrangements but which wasn’t the case here, which the employee wasn’t aware of and turned out to not that big of a deal for scale. Plenty of companies work in the background supporting other. Businesses and don’t always need attribution.
OP is trying to pigeonhole this into some sort of anti capitalist diatribe by trying to make it about individual employees wanting recognition and some big evil company is treating them like invisible cogs in the machine... which doesn’t make much sense since he asked for the company itself to be attributed, not individuals. It’s up to the company to reward and recognize employee contributions, not in some 3rd party partners announcements.
Plus he was always free to comment how he helped work on it or letting people know Scale had a role in helping make it (which are both common on HN). Only if the parent company tried to suppress that would this argument make any sense. But I don’t know why I’m bothering to counter such a position.
that's a strange response. i'm already clearly critiquing the dominant paradigm, capitalism. why would you just itemise a bunch of conventions from this paradigm, which i likely disagree with?
do you need hn to be an agreeable echo chamber for you?
capitalism depends on people not thinking thoroughly about the "deal" they are being drawn into. i'm here to harm this situation.
{kind=link}
We’ve built this index for autonomous driving datasets (https://scale.com/open-datasets) and are building that out for other domains right now.
Open source data has been a pillar to progress in ML (starting with ImageNet). It should continue to be the case that data that enables researches is sufficiently democratized.