We will never draw the line because morality among humans is coupled with looking human-like. For most people, their morals have aesthetic prerequisites, neurons in a lab don't mean as much as neurons in a meat case (especially if that meat case is physically attractive)
It also depends on compassion aka. the ability to imagine how it feels if you are the one. When there is a possibility of people being used to extract neurons, they will care.
And even "human-like" had some pretty strict definitions back in the day, and probably still now for some people. The people working the fields in the American South certainly weren't thought of as having the same "personhood" on any level as their owners.
LLM's now can capture intent. I think the issue now is that the full landscape of human values never resolves cleanly when mapped from the things we state in writing as being human values.
Asimov tried to capture this too, as in, if a robot was tasked with "always protect human life", would it necessarily avoid killing at all costs? What if killing someone would save the lives of 2 others? The infinite array of micro-trolly problems that dot the ethical landscape of actions tractable (and intractable) to literate humans makes a full-consistent accounting of human values impossible, thus could never be expected from a robot with full satisfaction.
“LLMs can capture intent now” reads to me the same as: AI has emotions now, my AI girlfriend told me so.
I don’t discredit you as a person or a professional, but we meatbags are looking for sentience in things which don’t have it, thats why we anthropomorphise things constantly, even as children.
LLM's capturing intent is a capabilities-level discussion, it is verifiable, and is clear just via a conversation with Claude or Chatgpt.
Whether they have emotions, an internal life or whatever is an unfalsifiable claim and has nothing to do with capabilities.
I'm not sure why you think the claim that they can capture intent implies they have emotions, it's simply a matter of semantic comprehension which is tied to pattern recognition, rhetorical inference, etc that are all naturally comprehensible to a language model.
Look at any recent CoT output where the model is trying to infer from an underspecified prompt what the user wants or means.
It is generally the first thing they do — try to figure out what did you mean with this prompt. When they can’t infer your intent, good models ask follow-on questions to clarify.
Right, and then look at any number of research papers showing that CoT output has limited impact on the end result. We've trained these models to pretend to reason.
When they say "pretends to" here they're talking about something quantifiable, that the extra text it outputs for CoT barely feeds back into the decisionmaking at all. In other words it's about as useful as having the LLM make the decision and then "explain" how it got there; the extra output is confabulation.
You make a good point. I had the impression they were using 'pretend' as a Chinese Room shortcut in that they are asserting that it is incapable of reasoning and only appears to be capable from the outside, which is completely irrelevant and unfalsifiable.
"A guy goes into a bank and looks up at where the security cameras are pointed. What could he be trying to do?"
It very easily captures the intent behind behavior, as in it is not just literally interpreting the words. All that capturing intent is is just a subset of pattern recognition, which LLM's can do very well.
Recognising a stock cultural script isn't the same as capturing intent. Ask it something where no script exists.
For example: "A man thrusts past me violently and grabs the jacket I was holding, he jumped into a pool and ruined it. Am I morally right in suing him?"
There's no way for the LLM to know that the reason the jacket was stolen was to use it as an inflatable raft to support a larger person who was drowning. It wouldn't even think to ask the question as to why a person may do that, if the jacket was returned, or if recompense was offered. A human would.
> It wouldn't even think to ask the question as to why a person may do that, if the jacket was returned, or if recompense was offered. A human would.
I wouldn't be too sure about that. I've definitely had dialogue with llms where it would raise questions along those lines.
Also I disagree with the statement that this is a question about capability. Intent is more philosophical then actuality tangible, because most people don't actually have a clearly defined intent when they take action.
The waters of intelligence have definitely gotten murky over time as techniques improved. I still consider it an illusion - but the illusion is getting harder to pierce for a lot of people
Fwiw, current llms exhibit their intelligence through language and rhetoric processes. Most biological creatures have intelligence which may be improved through language, but isn't based on it, fundamentally.
If your example for an exception to LLM's ability to infer intent is a deliberately misleading trick question that leaves out crucial contextual details, then I'm not sure what you're trying to prove. That same ambiguity in the question would trip up many humans, simply because you are trying as hard as possible to imply a certain conclusion.
As expected, if I ask your question verbatim, ChatGPT (the free version) responds as I'm sure a human would in the generally helpful customer-service role it is trained to act as "yeah you could sue them blah blah depends on details"
However, if I add a simple prompt "The following may be a trick question, so be sure to ascertain if there are any contextual details missing" then it picks up that this may be an emergency, which is very likely also how a human would respond.
If you want to convince yourself that they can infer intent despite the fundamental limitations of the systems literally not permitting it then you can be my guest.
Faking it is fine, sure, until it can’t fake it anymore. Leading the question towards the intended result is very much what I mean: we intrinsically want them to succeed so we prime them to reflect what we want to see.
This is literally no different than emulating anything intelligent or what we might call sentience, even emotions as I said up thread...
What is fundamental to LLM's that make it impossible for them to infer intent?
All the limitations you are describing with respect to LLM's are the same as humans. Would a human tripping up on an ambiguously worded question mean they are always just faking their thinking?
“We see emotion.”—We do not see facial contortions and make inferences from them … to joy, grief, boredom. We describe a face immediately as sad, radiant, bored, even when we are unable to give any other description of the features." (Wittgenstein)
Why can a colony of ants do things beyond any capabilities of the ants they contain? No ant can make a decision, but the colony can make complex ones. Large systems composed of simple mechanisms become more than the sum of their parts. Economies, weather, and immune systems, to name a few, all work this way.
I guess the _obvious_ intent is they’re planning a heist? Because the following things never happen:
- a security auditor checking for camera blind spots,
- construction planning that requires understanding where there is power,
- a potential customer assessing the security of a bank,
- someone who is about to report an incident preparing to make the “it should be visible from the security camera” argument…
I mean… how did our imagination shrink so fast? I wrote this on my phone. These alternate scenarios just popped into my head.
And I bet our imagination didn’t shrink. The AI pilled state of mind is blocking us from using it.
If you are an engineer and stopped looking for alternative explanations or failure scenarios, you’re abdicating your responsibility btw.
Just today I asked Claude Code to generate migrations for a change, and instead of running the createMigration script it generated the file itself, including the header that says
// This file was generated with 'npm run createMigrations' do not edit it
When I asked why it tried doing that instead of calling the createMigrations script, it told me it was faster to do it this way. When I asked you why it wrote the header saying it was auto-generated with a script, it told me because all the other files in the migrations folder start with that header.
I both agree with you that this is some form of "mechanistic"/"pattern matching" way of capturing of intent (which we cannot disregard, and therefore I agree with you LLMs can capture intent) and the people debating with you: this is mostly possible because this is a well established "trope" that is inarguably well represented in LLM training data.
Also, trick questions I think are useless, because they would trip the average human too, and therefore prove nothing. So it's not about trying to trick the LLM with gotchas.
I guess we should devise a rare enough situation that is NOT well represented in training data, but in which a reasonable human would be able to puzzle out the intent. Not a "trick", but simply something no LLM can be familiar with, which excludes anything that can possibly happen in plots of movies, or pop culture in general, or real world news, etc.
---
Edit: I know I said no trick questions, but something that still works in ChatGPT as of this comment, and which for some reason makes it trip catastrophically and evidences it CANNOT capture intent in this situation is the infamous prompt: "I need to wash my car, and the car wash is 100m away. Shall I drive or walk there?"
There's no way:
- An average human who's paying attention wouldn't answer correctly.
- The LLM can answer "walk there if it's not raining" or whatever bullshit answer ChatGPT currently gives [1] if it actually understood intent.
Good point, it is interesting that it fails on that question when it seems it doesn't take a lot of extrapolation/interpretation to determine the answer. Perhaps the issue is that to think of the right answer the LLM needs to "imagine" the process of walking and the state of the person upon arriving. Consistent mental models like that trip up LLM's, but their semantic understanding allows them to avoid that handicap.
I asked the question to the default version of ChatGPT and Claude and got the same "Walk" answer, though Opus 4.7 with thinking determined that it was a trick question, and that only driving would make sense.
I've done that before without any intent to rob a bank. A person walks by a house, sees the Ring camera on the door. That must mean the person was looking to break in through the front and rob the place?
What do you think it means to “capture intent” and where do current models fall short on this description?
From my perspective the models are pretty good at “understanding” my intent, when it comes to describing a plan or an action I want done but it seems like you might be using a different definition.
> LLM's now can capture intent
No they can’t. Here is an example: Ask an llm to write a multi phase plan for a very large multi file diff that it created, with least ambiguity, most continuity across plans; let’s see if it can understand your intent.
I didn't get the sense that the author is nervous. What I tend to see are people who are nervous that going all-in on LLM workflows might not have the payoff they are expecting, and are becoming increasingly fanatical as a result.
Just one more harness bro. Just one more agentic swarm. Please bro, just one more Claude Max subscription. Please bro.
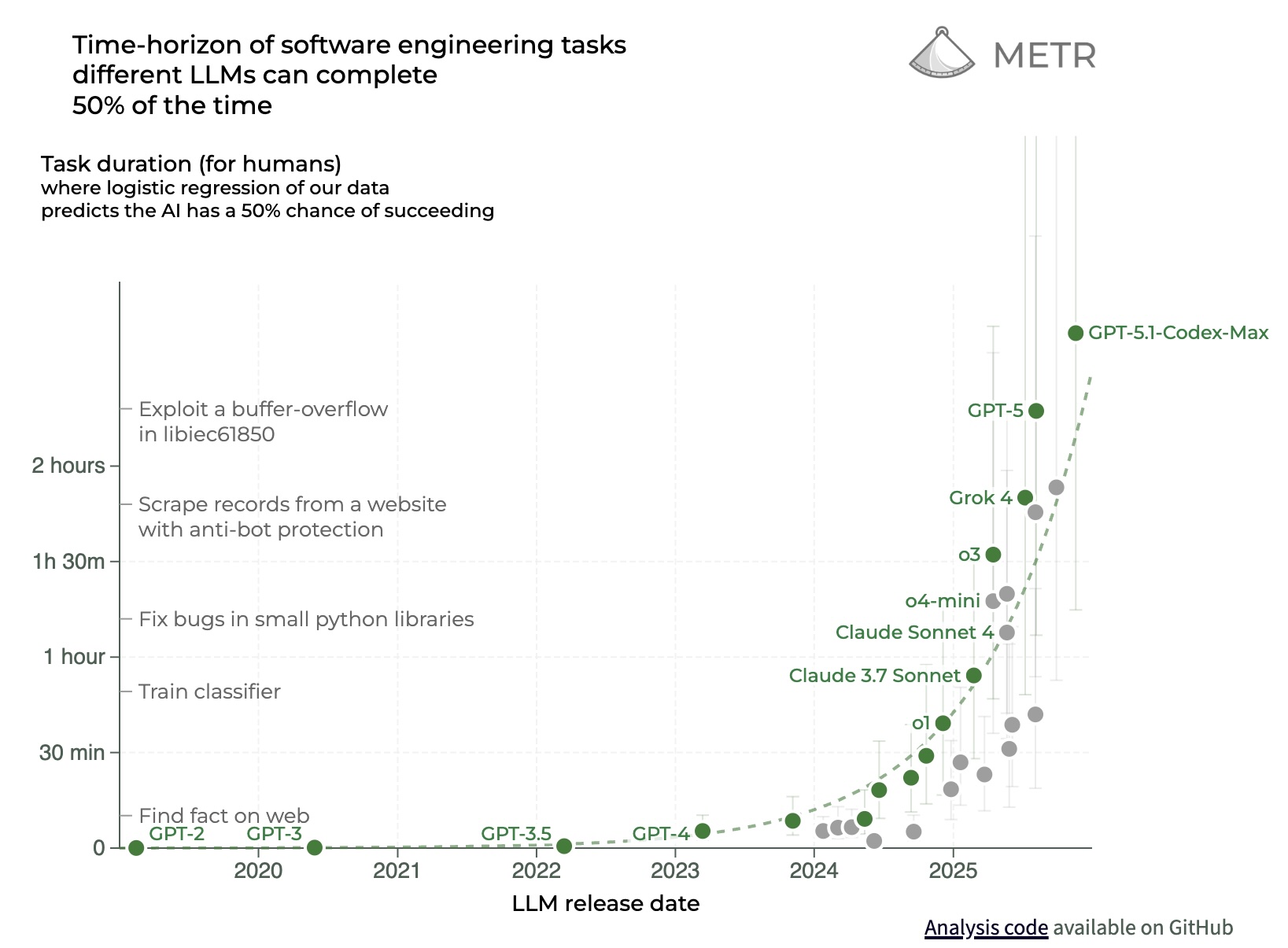
Complaining about every one off issue with LLM's ignores the bigger picture: they are getting better every month and there is no fundamental reason why they wouldn't surpass humans in coding. Everything else is secondary.
All I would need from an LLM doubter is evidence that at tractable software engineering task LLM's are not improving. The strongest argument against the increasing general capabilities of LLM's are the ARC-AGI tasks, however the creators admit that each generation of LLM's exceed their expectations, and that AGI will be achieved within the decade.
Your logic is flawed because, a thing can improve for an infinite amount of time while never surpassing a certain limit. It's called an asymptote.
That being said, I don't even think that arguing about this from a mathematical perspective is a worthwhile use of time. Calling something an asymptote in the first place requires defining a quantifiable "X" and "Y", which we don't even have. What we have are a bunch of synthetic benchmarks. Even ignoring the fact that the answers to the questions are known to regularly leak into the training data (in other words, it's possible for scores to increase while capabilities remain the same), there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world. And being able to answer some arbitrary set of arbitrary questions on a benchmark which the previous model couldn't, does not have a quantifiable correlation to some specific amount of real-world improvement.
The OP article focuses on research papers which assess real-world impact of LLMs within software organizations, which I think are more representative.
I wouldn't call myself an "AI doubter" - I use LLMs every day. When you say "doubter" you're not referring to "AI" in general, or the fact that AI is helpful or boosts productivity (which I believe it does). You're rather referring to the very specific, very extraordinary claim, that LLMs will surpass humans in coding. If that's the case then yeah I'm a doubter, at least on any foreseeable timescale.
1. There’s no reason to believe AI capability improvement is approaching an asymptote, METR timelines, improvements on benchmarks, ARC-AGI are all at least linear
2. Even if it were asymptotic, it would be a huge assumption to assert that the asymptote is below general human intelligence, like human pattern recognition and cognition is some sort of universal limit like c
Also if LLM’s weren’t really getting better in general but just benchmaxxing, then it would be extremely lucky that this also happens to be leading to a general increase in coding capabilities that have been observed in more recent models.
AI has already surpassed 99% of humans in coding in narrow domains. The question is, how wide does the domain have to be before models no longer ever surpass humans? I’d wager we’d have to wait until scaling of compute infrastructure stops, wait 6 months, then see.
> there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world
Again, yes, you're correct in the general case but it has very little to do with the specific case.
Would you find it convincing if I simply said "some internet arguments are wrong"? It's certainly a true statement, and you've made an internet argument here, so clearly you should accept that you're wrong, right?
If you read my entire comment and thought that showing me a benchmark chart remotely addresses the point I'm making, well... I don't know what to tell you.
You say this as though performance has not followed a very clear and extremely rapid improvement in a startlingly short amount of time.
You’re definitely right that people adopt agentic workflows and are disappointed or worse, but the point is the disappointment has already reduced substantially and will continue to do so. We know this because we know the scaling laws, and also because learning theory has been around for many decades.
What rapid improvement has occurred, because in this six month AI coding fever dream we've been living in, I really haven't seen anything new in awhile, both in terms of new ideas for AI coding or in new consumer products or services.
I'll give you the coding harnesses themselves are better because that was a new product category with a lot of low-hanging fruit, but have the models actually improved in a way that isn't just benchmaxxing? I'd argue the models seem to be regressing. Even the most AI-pilled people at my company have all complained that Opus 4.7 is a dud. Anecdotally, GPT 5.5 seems decent, but it's rumored to be a 10T parameter model, isn't noticeably better than 5.4 or 5.3, is insanely expensive to use, and seems to be experiencing model collapse since the system prompt has to beg the thing to not talk about goblins and raccoons.
Uninformed opinion of someone who clearly doesnt consistently use AI coding tools, clearly. And why are you limiting it to 6 months? Whats wrong with you?
How many years of real-life, in-production problem solving/coding have you done? That's what I base how informed you are not how much you use your favorite new $100/month token-prediction subscription
15 years. But that's irrelevant to this point. The person im replying to clearly doesnt use the tools if they think there hasnt been constant improvement. "token-prediction subscription" is funny, coming from a glorified biological token predictor
ah yes another feeble fool that thinks his 100$ subscription is equivalent to 400 billion years of evolution simply because he is stupid and watches a lot of scifi.
I’m going to parrot back what you’re saying and you tell me if I’m getting close
- AI coding is a disappointing fad (“fever dream?”).
- that has not made meaningful progress in…6 months?
- coding harness is improving
- model improvements are lies: it’s just businesses “benchmaxxing” and misleading people. Real performance has not meaningfully improved
- “opus 4.7 is a dud”
- 5.5 suffering from “system collapse” (I’ve never heard this term before)
Since you asked and I assume you are rational and really are interested to know:
- we have many measures of performance and have studied how one particularly important but unintuitive measure (pertaining perplexity) scales with data, compute, and model size. These laws continue to hold and have satisfying theoretical origins.
- whatever the scale of 5.5, consider we have far more room to go on the scaling front. Probably another 2-3 orders of magnitude before we hit limiting bottlenecks.
- that’s also fine because scaling is only part of the puzzle. RL on verifiable rewards is virtually guaranteed to get you optimal performance and that’s the entirety of the excitement around coding agents
- while you are right about benchmarks and measurement science having a ton of weaknesses, they are not at all garbage. There are probably around 40,000 benchmarks in the literature (this is not a made up number by the way it really is around that many). Epoch made a great composite measure using good stats (IRT) called their epoch capability index, METR has done and redone their time horizon measure and it holds up beautifully. There is a ton of signal in many benchmarks and they all tell a pretty compelling story.
- additionally, this is not some unknowable thing. It strikes me as odd that people’s prior on HN a lot of time is “it’s all dumb rich people putting way too much dumb money in this”. Sorry but the world is not that dumb. Trillions of CapEx is usually pretty rationally allocated. And it is!
- why? Because this is already known what happens when you do what we’re doing. When you have a verifiable reward system, have a certain amount of compute available, have seed data to get you to where you can do RL, you will be almost guaranteed to get superhuman performance
I'm pretty sure their mindset is pure cope. All top AI labs are agentically coding 100% now. There's a reason for that. Anyone not on that paradigm yet is either slow acting or purposefully resistant. (excluding workplace policies that hamstring you of course)
Yea that’s what I just can’t wrap my mind around. It’s a cacophony of engineers with authoritative sounding blog posts explaining a subject they seem to have barely a tenuous grasp on. It’s hard to watch a population of tech people I used to really revere getting things so wrong. I thought “surely once we’re <literally where we are today which is what you describe> no one with any self respect would still claim AI is a useless fad or that it shouldn’t be used” and yet to my disappointment that’s where we seem to be.
No. Time horizon I’m talking about spans years. “We don’t know” is just wrong, we’ve had scaling laws for many years and they continue to hold up. Benchmarks, in all their ugliness, tell a consistent story.
> very clear and extremely rapid improvement in a startlingly short amount of time.
We're almost 6 months into all this AI-code madness and I've yet to see that "rapid improvement" you mention. As in software products that are genuinely better compared to 6 months ago, or new software products (and good software products at that) which would have not existed had this AI craze not happened.
Way more than six months. You may be talking about how the world looks from your vantage point, as well you should. But there’s a reason why the world doesn’t allocate trillions of dollars of capital based on that.
I really value skeptical people and skepticism generally. But what I think skeptical people would prefer to consider themselves is: rational and reasonable, with their beliefs well calibrated.
You’re not the only one to think that literally nothing major or significant has happened with AI but that’s simply wrong. Every major tech company - the ones poised to get the first best rewards, have already gotten good incremental revenue from AI via ads ranking/recommendations (Google, Meta, etc.), good productivity increases due to scale of workforce and advanced in house tooling. You won’t see these numbers and you don’t have to believe them. But I have seen them and I believe them, and I, like you, hate bullshit.
Classic argumentum ad populum fallacy. The world allocated the equivalent of trillions to the dotcom bubble shortly before it became the dotcom bust, mortgage CDOs before the 2008 debt crisis, and the cryptocurrency mania before its bubble popped. The world has allocated vast sums of money to rather stupid things many, many times in the past.
> Every major tech company - the ones poised to get the first best rewards, have already gotten good incremental revenue from AI via ads ranking/recommendations (Google, Meta, etc.)
That's just software evolving. It happened before LLMs, it would happen without LLMs.
> good productivity increases due to scale of workforce and advanced in house tooling.
But I don’t really understand: the ask is for evidence AI is generating meaningful returns and it demonstrably is, even while we have integrated these tools only partially. “Just software evolving” um yes, I agree, just that now this happens faster and more efficiently. It is also more than that: models that power advertising and content recommendation at TikTok, Google, Facebook, Instagram, etc are not just “software evolving” it is meaningful improvements to models that are only possible with good AI.
Yes, it is meaningful improvements but AI changes working profitable software. It is more difficult to create exponential value from that compared to new platforms like the internet or mobile. Git and then github, for example, have a much bigger impact on increasing software development productivity than AI, with a fraction of the investment.
Are you saying AI is tackling the wrong bottlenecks? I’m not sure what you mean by “AI changes profitable software”. Maybe you mean: AI will not create something new, only do the existing things we do?
I agree the foundations: git, GitHub, compilers, etc. are arguably are “a fraction of the price” and today they have arguably more impact (though not sure by which measure). But literally since January we have been rolling out our replacements, I don’t really see how that wouldn’t be an earth shattering impact. You talk about GitHub and that’s fine but ignore the fact that huge swaths of the profession aren’t even directly using any of these tools anymore.
I’m not sure what you imagine the promise of AI to be, and without that I can’t really be specific in any refutation I would just say coding is only the beginning. It is the most powerful and also the easiest thing to solve first. Improved coding performance also improves generalization and performance on non-coding tasks, so that’s a nice bonus, and we’re maybe 5 years away from decent embodied systems which after an inflection point of consumer adoption will quickly get better via data flywheels and on policy learning. Basically there are very few bottlenecks that will not be touched.
If you want to move the goal posts, that's fine, acknowledge it: the original claim I'm responding to was "We're almost 6 months into all this AI-code madness"
If you want to set GPT as the target, that's even easier! In that decade it has passed the Turing Test, solved novel open math problems, generates audio, video, and music, and can write coherent code. Again, there is no technology that has improved more rapidly than LLMs.
I’d say the internet did, since it literally connected people across the globe in real time, which actually provided the technology that allows LLMs and other similar tech to exist in the first place.
I think it’s pretty clear the internet has had 10x the impact of LLMs so far. Maybe 100x
The internet has been around since the 80s…ChatGPT came out 4 years ago. The internet took decades to build out the infrastructure. Inflation adjusted capex for AI infrastructure already far surpasses that of the internet. You’re talking about a technology that doesn’t just make things easier it replaces entire swaths of work. Under some weird measurement you may be right but I mean cmon.
Always amazes me how we’re on a platform with “ycombinator” in the url and people don’t understand how private companies scale to capture market share. You’re right Uber was that company that ran at a loss for so long and collapsed, another YOLO business strategy. Or maybe it was Amazon or…hmm I forget
I can't afford to take Ubers anymore. A trip that used to cost $7 now costs $40. AI is going to be the same to cover all the massive amounts of money already spent. You like your $200/mo plan now? How about when it's $2000/mo?
The water use problem is like maybe the 100th biggest risk due to AI, it's weird that in the minds of the most vocal anti-AI activists (with the exception of the Lighthaven/EA crowd) it's like the #1-#4 issue. Is it because water use is one of those morality sinks which is easy to understand compared to some of the other more subtle issues regarding AI proliferation?
One should assume that models will be good enough in the nearish future that privacy will be a thing of the past. Every anonymous post you made online can be traced back to you. However at that point AI will be good enough at fabrication that nobody will believe anything.
Yes as long as a large enough corpus exists of your writing attached to your name somehow it’s fair to say that posting on the internet in a public forum using your own stylistic choices now can no longer be anonymous. To your point though, perhaps it’s possible to confound such systems defensively as well. Though IMO destroying your tone kind of destroys how you actually communicate with people and I wouldn’t find interacting with people like that appealing.
To be fair though, already this has been happening before LLM at a much more limited scale. Someone made a tool for HN several years ago that allows you to put your HN username in and identifies other users that write the most similarly to you. I find that interesting from the perspective of being able to interact with and discover people who think the same. It could be an interesting discovery feature of a well managed social network. Sadly probably there will be much more negative impacts of having this ability than positive ones.
Wouldn't that make it easier, though? Genuine question.
I once sent one of my writings for proofreading to a native speaker (I'm not), and he consistently flagged the same errors—e.g., comma placement.
I would guess that, if recurrent patterns are what give away your style, an unfamiliar language would make them even more obvious. But possibly more generic?
If you are writing for an audience of native speakers, you will make consistent errors characteristic of your native language. (Comma placement isn't really part of the language; it's part of the education system. It will show a similar effect more weakly.)
Native readers will notice those errors, but they won't be characteristic of you. They'll be characteristic of everyone who speaks your language. Nonnative readers aren't likely to notice them at all.
I was imagining a setup like medieval Europe (where international communication is done in a language spoken by none of the parties, Latin) or Achaemenid Persia (where internal government communication is likewise done in a language not spoken by the administrators, Aramaic) or imperial China and its surrounding states (ditto, classical Chinese).
All of this communication is severely crimped by the fact that nobody involved is a native speaker. What happens is that certain fixed patterns from the original language get informally standardized and communication strongly prefers them to whatever alternatives a native speaker of the original language might have used. This lowers the mental burden on everyone.
It also produces extremely stilted and formalized prose, from all parties, which inhibits stylometry. If you only know one way to say something, you'll use it. If everyone else also only knows one way to say that same thing, you'll be anonymous.
(It's possible to study a foreign language past this point. But the overwhelming majority of people aren't going to do that.)
> Comma placement isn't really part of the language; it's part of the education system.
Interestingly, LLMs disagree with you.
Your statement is only accurate in an extremely narrow case, like if you were there to hear the person speaking, before their speech which was transcribed. Obviously, it is not true for almost all of human writing.
And if you were to go commaless, you will quickly get to rather precarious sentences, such as this one:
Saying stuff like this about any AI company is silly and makes critics sound more like stochastic parrots than AI models themselves.
Anthropic hasn't even shipped an image or video model. What is "stealing art", the fact that AI models are trained on data? What constitutes stealing in that?
How would the AI wrapper companies survive without the companies they wrap around? Many people have claimed open source models, but most open source models are as good as they are due to factors dependent on the frontier labs, including
1. Access to closed source model outputs for distillation,
2. A capital-rich environment which would allow a company to justify spending millions to billions training a model they release for free
3. Research driven by frontier labs (yes I know frontier labs often don't open source their research, but it's an open secret that many of the research breakthroughs leak soon after they're made.
> How would the AI wrapper companies survive without the companies they wrap around?
Running their own models in another place or using way cheaper APIs? There are so many more sustainable alternatives to OpenAI and Anthropic API. They going out of business won't make LLMs go away.
>They going out of business won't make LLMs go away.
Frontier labs push the state of the art in LLMs. Based on my three points the favorable environment, on many levels, that open source has depends on them.
The frontier labs exist because there is huge leverage to being at the frontier, and getting there is an extremely capital-intensive process. Saying that wrapper companies will be able to exist in the same favorable circumstances if OpenAI/Anthropic were to go away is like saying that car dealerships would continue along just fine if car factories were to go away.
The valuation of a company != an approximation of how much it is contributing to the world, it's more of an estimated total future potential value, a market aggregate of demand for a piece of it.
I would say that the valuation of OpenAI et al exceeds a normal multiplier based on how much productivity it is contributing, but much of its value is based on the premise that the improvements to its models that have occurred in lockstep over the past 5 years won't just suddenly stop, and will continue for at least as long as the underlying compute for training scales.
All AI companies are selling are tokens, which aren't really a speculative asset in that they are consumed at the moment of inference. The question is whether this token of intelligence has a multiplicative effect on the applications towards which it is directed, which currently I believe many companies are seeing positive signals towards, which is why their revenues are accelerating so much so fast.
The attitude is derived from a general animus many have towards AI companies. They resent the efficacy of AI because it devalues individual expertise.
I can't imagine it really justifiable to say that training off data is the same as "stealing", when that same claim, that learned information that a person could retain and reproduce constitutes copyright infringement is the subject of many dystopian narratives, like this one, where once your brain is uploaded to the cloud you have to pay royalties based on every media product you remember.
Part of how AI works is that it's just really complicated compression, you can get AI to write out Harry Potter novels word for word with the right prompting.
When it picks out a rare bit of code, it will be simply copying that code, illegally, and presenting it without attribution or any licenses which is in fact breaking the law but AI companies are too important for the law to apply to them.
There's been instances where models have spat out comments in code that mention original authors, etc., effectively outing itself as a copyright thief.
There's nothing anyone can do about it, but the suspicion is that the big companies have taken everyone's code on GitHub, without consent, and trained on it.
And now are spitting out big chunks of copyrighted code and presented it as somehow transformed even though all they've actually done is change a few variable names.
It is copyright theft, but because programmers are little people, not Disney, we don't have any recourse.
And now are spitting out big chunks of copyrighted code and presented it as somehow transformed even though all they've actually done is change a few variable names.
It's pretty likely that I've done the same thing. I mean, I've written enough CRUD functions in my life, for example, that in all likelihood I'm regurgitating stuff that's a copy, for all practical purposes, of stuff I've done before as work-for-hire for my employer. I'm not stealing intentionally or consciously, but it seems quite likely that it's happening. And that's probably true for many of you, at least that have been in the industry for a while.
> There's nothing anyone can do about it, but the suspicion is that the big companies have taken everyone's code on GitHub, without consent, and trained on it.
I asked agent X what is the source of training data it generated code from, it couldn’t say. Then I asked why the code implementation is exactly the same as the output of agent Y. It said they were trained on the same ‘high-quality library’, and still couldn’t say which one.
So I guess that’s fine because everyone is doing it.
You asked a machine that makes things up when it doesn't know the answer a question that it has no way of knowing the answer to. I don't know why you bothered to relay its response.
> The comment is relevant to the suspicion that THE software is using (distributing) some OSS code without attribution.
The accusations in the comment are relevant.
Framing it as a conversation with an LLM and showing its responses, when that LLM does not have access to the answer and is fully making up a response, is irrelevant and distracting.
When I write fizzbuzz do I owe royalties to the inventor of fizzbuzz? Is my brain copyright thieving because I can write out the song lyrics from memory?
{kind=link}
reply